

 데이터 리터러시 #2
데이터 리터러시 #2
데이터 과학자의 가설 사고 2장을 읽고 정리해 본 내용이다. 2장에서는 데이터를 읽는 방법을 소개하고 있다.EDA(Exploratory Data Analysis, 탐색적 데이터 분석) 과정을 의미하기도 한다.도메인 -> 특징&경향 -> 세부내용 -> 관계 파악목적 즉, 데이터의 도메인을 생각하고 특징과 경향(평균, 중간값, 분포 등)을 파악하고 세부내용(상이값, 이상값 등)을 살펴보고 데이터 사이의 관계(상관관계, 인과관계)에 대해서 살펴보는 과정이다. 1. 생각하면서 데이터를 읽자 데이터를 읽을 때에는 배경 즉, 데이터 도메인을 알아야 한다. 영화 판매 데이터를 본다고 할 때 영화의 lifecycle 을 전혀 모르고는 데이터를 정확히 파악하기 어렵다. (실제로 데이터 과학자들은 실생활 데..
 데이터 리터러시 #1
데이터 리터러시 #1
데이터 과학자의 가설 사고 1장을 읽고 정리해 본 내용이다. 데이터 리터러시를 배우기 위해 기초적인 소양으로 아래 3가지를 언급하고 있다. 데이터를 읽는 힘 데이터를 설명하는 힘 데이터를 다루는 힘 책의 목차를 보면 아래와 같이 이뤄지고 있다. 데이터를 읽고 -> 설명하고 -> 분류하고 -> 규칙을 발견 (insight) -> 예측한다. 데이터 과학자란? 데이터에서 가치를 창출하고, 비즈니스 과제에 답을 찾는 프로세셔널 데이터 과학자는 결국 읽고, 설명하고, 분류하고 그 속에서 Insight 를 찾고 예측하는 모든 능력을 보유해야 한다.
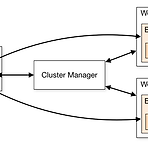 Spark Memory Tuning Case-Study
Spark Memory Tuning Case-Study
Spark 기본 구조 Spark Memory JVM 내부 Reserved Memory Spark Memory Execution Memory (operation) Storage Memory (cache): RDD Persistance JVM 외부 OffHeap Memory External Process Memory 5GB 기준 메모리 영역 예제 Q) 빠르다고 해서 Spark 를 사용하는데, 느려요~??? Memory 는 충분한가? 무한정 늘릴 순 없다 YARN (Resource Manager) 적절히 분배해 주는가? => Spark Properties 정해진 메모리를 효율적으로 사용하고 있는가? spark.executor.memory 늘려준다 spark.executor.cores 조정 (얼마가 적당할까?)..
ffmpeg 을 통해 영상으로 부터 이미지를 추출 하려고 하는데, 아래와 같이 오류가 발생했다. (ffmpeg -version 은 아래와 같다) ffmpeg version 6.0 Copyright (c) 2000-2023 the FFmpeg developers built with Apple clang version 14.0.3 (clang-1403.0.22.14.1) configuration: --prefix=/opt/homebrew/Cellar/ffmpeg/6.0_1 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags= --enable-ffplay --enable-gnutls --enabl..
- Total
- Today
- Yesterday
- bigdata
- spark
- CI
- flume
- json
- Django
- Sqoop
- 통계학
- PYTHON
- 알고리즘
- Apache Spark
- jenkins2.0
- exception
- mongodb
- mysql
- spring
- 확률분포
- linux
- java
- 책요약
- jenkins
- db
- Oracle
- HADOOP
- 태그를 입력해 주세요.
- Learning Spark
- mongo
- Git
- jackson
- Hdfs
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |