데이터 과학자의 가설 사고 4장을 읽고 정리해 본 내용이다.
3장에서 데이터 비교는 Apple to Apple 처럼 비슷한 분류의 데이터 사이에 이뤄져야 한다고 언급했다. 그렇다면 비슷한 데이터들끼리 분류가 필요하다. 4장에서는 데이터를 어떻게 분류하고 그룹핑하는지 소개하고 있다.
- 특징이 비슷한 데이터로 그룹을 만드는 방법
- 목적에 따라 데이터를 분류하는 일의 중요성
- 데이터를 기계적으로 분류하는 방법
- 데이터를 분류하는 순서
특징이 비슷한 데이터를 그룹화하자.


어느 카페에서 커피와 디저트 주문 횟수를 시각화 한 사례이다. 대략 손님을 그룹핑하면 우측 그림처럼 될 것이다. (책에는 3가지 선택지를 가진 퀴즈로 소개하는데, 간단한 부분이라 생략하고 정답만 소개한다) 그룹1, 2, 3으로 나눠진 기준은 무엇일까?
- 그룹1: 커피/디저트 주문량이 많은 손님
- 그룹2: 커피 주문은 많으나 디저트 주문은 적은 손님
- 그룹3: 커피/디저트 주문량이 적은 손님
어렵지 않게 특징이 비슷한 손님들을 구분할 수 있다. 그렇다면 이렇게 그룹으로 나눠야 하는 이유는 무엇인가? 위 사례에서는 9명의 손님을 3그룹으로 나누어 보았다. 현실 세계에서 손님이 9명인 카페가 있다면 문을 닫아야 할 것이다. 실제로는 동네 작은 카페라도 손님수는 많을 것이다. 즉, 대량의 데이터는 몇 개의 그룹으로 구분해서 보면 비교, 분석하기 쉬워진다.
다시 카페 손님을 구분한 사례로 돌아와 보자. 3그룹으로 나눴고, 어떤 특징이 있는지도 살펴 보았다. 모든 카페의 목적은 돈을 버는 것이기에 매출 증대를 위해서는 어떤 방법이 있을까? 모든 손님이 그룹1의 특징을 보여준다면 제일 좋을 것이다. 하지만 그룹3의 손님들이 갑자기 그룹1 손님의 특징을 보일 순 없다. 그룹 3 -> 2 -> 1 순서로 유도가 필요하다.

YES24 에서 책을 구매하려고 하면 아래와 같이 나와 비슷한 유형의 고객(동일한 책을 구매한 사용자)이 구매한 책들을 추천해 준다. 비슷한 특징의 고객으로 그룹핑해서 추천해 주는 것이다. 대부분의 추천 로직은 어떤 특징을 기준으로 그룹핑하여 추천한다. (AI가 도입이되면서 이 특징 수는 상상을 초월하게 되었다. -> 특징 수가 높아 질수록 개인화 추천에 가까워진다.)

특징이 비슷한 고객군을 분리하는 것이 분석에 용이하다는 것을 확인할 수 있는데, 그럼 특징이 비슷하다는 판단은 어떻게 하는 것일까? 데이터 사이의 거리를 계산해 볼 수 있다. 카페의 사례로 다시 돌아가 보자.
(A, D, F), (C, E, I), (B, G, H) 각 그룹 사이에는 가까운 것을 확인할 수 있다. 2차원에서 데이터 사이의 거리는 두 점의 거리로 생각할 수 있으며, 이는 (수학시간에 배운) 피타고라서 정리 공식으로 계산해 볼 수 있다. Scale이 다른 경우는 어떠한가? 키와 몸무게를 비교한 경우는 단순히 데이터 간의 거리로 비교하기는 어렵다. 이때 활용할 수 있는 것이 데이터 표준화(평균값을 0, 분산을 1로 만드는 처리)를 하여 Scale을 맞춰주는 작업을 한 뒤 비교한다.


목적에 맞게 데이터를 분류하자.
앞 장에서 데이터를 그룹으로 나누는 방법을 확인했다면, 이번 장에서는 왜 나눠야 하는지 무엇을 위해 나눠야 하는지 목적에 대해서 고민해 보자. 아래와 같은 퀴즈가 책에서 소개되고 있다.

위 표에서 A~H 학생을 분류해 본다면 어떻게 할 수 있을까?
- 전체 과목 평균?
- 공부 과목과 운동 과목(체육) 구분하여 평균?
- 이과/문과 과목을 구분하여 평균?
어떤 부분을 확인하고자 분류를 하는지 목적을 알 수 없기에 모두가 가능한 분류 방법이다.




데이터를 분류할 때에는 왜? 어떤 목적을 가지고 분류를 하는지 정의하는 것이 무엇보다 중요하다. 위 케이스에서는 "성적이 우수한 학생을 알고 싶다", "문과 선발 코스와 이과 선발 코스를 추천할 학생을 고르고 싶다" 등의 목적을 알수 없기에 어떻게 분류해서 보는게 나은지 알 수 없다. 현실에서는 분류 기준이 2차원이 아닐 수 있기에 목적을 명확히 수립하더라도 쉽지 않은 경우가 많지만 꼭 선행 되어야 하는 작업이다.
데이터를 기계적으로 분류하자.
지금까지 퀴즈에서 다뤘던 데이터는 대략 눈으로 나눠볼 수 있는 아주 적은 데이터였다. 현실 세계에서 데이터 수는 어마어마하다. 수백만 수천만 이상의 데이터들을 다뤄야 할 것이다. 이를 구분하려면 단순히 산포도 등으로 시각화 해 보고 눈으로 그룹핑을 할 순 없다. 이럴 때 통계해석 툴이나 머신러닝 Lib 들을 사용해서 분류할 수 있다.
수많은 Lib 와 알고리즘, 딥러닝 세계에서는 모델들도 많이 있으나, 여기에서는 기초적인 부분만 다루고 책에서는 Clustering 에 기본적으로 사용했던 k-means 알고리즘을 소개해고 있다. k-mean 는 주변 몇개의 지표의 평균을 기반으로 그룹핑을 한다는 가장 기본적인 개념이다.


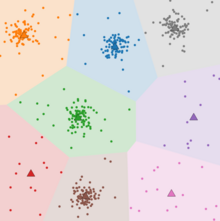
k 값과 클러스터 수의 차이가 있을 때 한계점을 드러 내기도 한다. (좌측은 k 값이 작을 때, 우측은 k 값이 클 때 사례이다) k-means 에서는 초기값을 어떻게 선정하느냐에 따라 성능이나 결과에 큰 영향을 미친다. 그러다 보니 k-means 에서 변형된 알고리즘들이 많이 있다.
- k-평균++ : 일반적으로 데이터 마이닝에서 사용
- k-중간점 : 평균 대신 중간점 활용
- k-중앙값 클러스터링 : 평균 대신 중앙값
- 퍼지 C-평균 클러스터링
자세한 내용은 wikipedia 나 책을 찾아보면 된다. 이미 구현된 python 함수들이 있고, 고도화된 알고리즘도 많다. 결국 딥러닝도 구분하기 위함이고 Activation Function 과 Error Optimization 을 통해 정확도를 올려과는 과정에서 복잡한 계산식을 사용하는 것 뿐이다. (구분 = 클러스터링에서) 기본 개념은 동일하다.
(책에서 소개하고 있는 k-means 를 적용해 본 샘플이다.)


3가지 그룹으로 나눠졌고, 프로모션을 위해 쿠폰을 지급한다면 어떤 쿠폰을 지급하는 것이 맞을까?
- 그룹1: 고기 마니아
- 그룹2: 이탈리안 마니아
- 그룹3: 카페 마니아
각 그룹이 좋아하는 음식에 관련된 쿠폰을 지급하는 것이 홍보 효과를 좀 더 극대화 하는 방법일 것이다. 이처럼 데이터를 그룹핑 함으로써 후속 대책에 대해서 좀 더 효율적으로 세울 수 있다.
여기까지는 다소 심플해 보이지만 딥러닝 (요즘은 LLM) 이 대세가 된 지금 위에서 언급한 그룹 3가지가 극한값으로 갔다고 생각하면 된다. 즉, 그룹이 아주 잘게 나눠져 (마치 1개의 그룹 내에 1명의 사용자만이 있는 것처럼) 개인화 추천이 있는 것처럼 말이다. 데이터 분석과 AI 는 다소 다른 기술이지만 기반이 되는 데이터 기준 의사결정이라는 것에서는 그 결을 같이한다.
'BigData > Data Science' 카테고리의 다른 글
| 데이터 리터러시 #6 (0) | 2024.05.11 |
|---|---|
| 데이터 리터러시 #5 (0) | 2024.05.09 |
| 데이터 리터러시 #3 (1) | 2024.04.25 |
| 데이터 리터러시 #2 (0) | 2024.04.24 |
| 데이터 리터러시 #1 (0) | 2024.04.17 |



