#1 을 해봤다면, 조금 불편함을 느꼈을 것이다.
분석 대상 파일과 output 경로를 모두 code에 포함되어 있기 때문이다.
그렇다면 이런 값들을 파라메터로 받아서 처리할 순 없을까?
spark-submit으로 수행시에는 AppClass 내에 파라메터를 전달할 방법이 마땅치 않다.
위 블로그를 참고하여 진행해보자.
우선 아래와 같이 Argument를 파싱하는 Enum을 생성해 보았다.
public static void main(String[] args) throws Exception {
if (ArrayUtils.getLength(args) > 4) {
LOGGER.debug("");
LOGGER.debug("Usage : ArgumentSampleApp <sourceFilePath> <outputFilePath> [appName] [hadoop uri]");
System.exit(1);
}
String sourceFilePath = ARGUMENT.SOURCE_FILE.getArgument(args);
String outputFilePath = ARGUMENT.OUTPUT_FILE.getArgument(args);
String appName = ARGUMENT.APP_NAME.getArgument(args, DEFAULT_APP_NAME);
String hdfsUri = ARGUMENT.HADOOP_URI.getArgument(args, DEFAULT_HDFS_MASTER_PATH);
ArgumentSampleApp app = new ArgumentSampleApp();
app.executeSparkTask(appName, hdfsUri, sourceFilePath, outputFilePath);
}
enum ARGUMENT {
SOURCE_FILE(0),
OUTPUT_FILE(1),
APP_NAME(2, true),
HADOOP_URI(3, true);
private int index;
private boolean isOptinal;
private ARGUMENT(int index) {
this(index, false);
}
private ARGUMENT(int index, boolean isOptinal) {
this.index = index;
this.isOptinal = isOptinal;
}
public String getArgument(String[] args) throws IllegalArgumentException {
return this.getArgument(args, StringUtils.EMPTY);
}
public String getArgument(String[] args, String defaultValue) throws IllegalArgumentException {
if (ArrayUtils.isEmpty(args)) {
return defaultValue;
}
int argsCount = ArrayUtils.getLength(args);
if (argsCount < this.index + 1) {
if (!this.isOptinal) { //필수 파라메터가 누락된 경우
throw new IllegalArgumentException();
}
return defaultValue;
} else {
return args[this.index];
}
}
}
|
간단한 기능이지만 필수정보와 옵션을 분리하여 기본값을 세팅할 수 있는 구조로 만들어보았다.
이런 기능을 제공해주는 OtpionParser가 있는 것으로 알고 있다. 테스트가 완료되면 그 Class를 적용하도록 하자.
일단 여기서는 위 샘플대로 테스트를 진행한다.
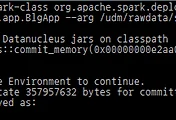
수행은 spark-submit 이 아닌 spark-class로 수행해야 한다.
~/apps/spark/bin/spark-class org.apache.spark.deploy.yarn.Client --jar hdfs://dev-umn-udm001.ncl:9000/umon-udm-1.0.0.jar --class com.nhncorp.umon.spark.app.ArgumentSampleApp --arg /README.md --arg /README2 --arg /ArgumentSampleApp2
|
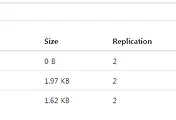
output이 지정한대로 README2 디렉토리에 잘 저장이 되었다.