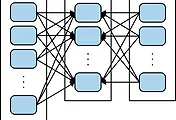
RDD 란?
An RDD in Spark is simply an immutable distributed collection of objects.
스파크에서 RDD 란 수정불가능한 분산 Collection 이다. 각 RDD 는 여러 node에서 다룰 수 있도록 여러 조각으로 나눠서 처리된다.
RDD 기본.
RDD를 생성할 수 있는 방법에는 두 가지가 있다.
- 외부 데이터 셋을 로딩
sc.textFile(“README.md”) 처럼 local storage 나 HDFS 에서 파일을 읽어 RDD 로 생성 - 기존 데이터 Collection 을 기반으로 생성
sc.parallelize(Arrays.asList(“test”, “test2”)); 처럼 기존 데이터로 생성
RDD 에는 두 종류의 operation 을 가진다.
- Transformation(변환)
대표적인 것이 filter() 이다. RDD 에서 특정 조건에 맞는 데이터만 골라 낼 때 사용한다.
Transformation 의 특징은 Lazy Evaluation 이다. filter 라는 함수가 호출되었을 때 실제로 RDD 의 데이터를 읽지 않는다.
|
package com.tomining.spark.tutorial.example;
import java.io.Serializable; import org.apache.commons.lang3.StringUtils; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; public class FilterWord implements Serializable { public void execute(final String filterWord) { SparkConf conf = new SparkConf().setMaster("local").setAppName("FilterWord"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile("REAMME.md"); JavaRDD<String> words = lines.filter(new Function<String, Boolean>() { public Boolean call(String source) throws Exception { return StringUtils.contains(source, filterWord); } }); } }
|
filter() 수행시 REAME.md 파일을 실제로 읽지 않는다. filter() 결과인 words RDD 도 실제 데이터 형태로 남아 있는 것이 아니다.
- Action(작업)
Driver Program 의 결과가 되거나 외부 저장소에 결과정보를 작성하는 Operation 이다.
filter() 함수를 사용한 예제를 좀 더 확장해보자.
|
package com.tomining.spark.tutorial.example;
import java.io.Serializable; import org.apache.commons.lang3.StringUtils; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; public class FilterWord implements Serializable { public void execute(final String filterWord) { SparkConf conf = new SparkConf().setMaster("local").setAppName("FilterWord"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> lines = sc.textFile("REAMME.md"); JavaRDD<String> words = lines.filter(new Function<String, Boolean>() { public Boolean call(String source) throws Exception { return StringUtils.contains(source, filterWord); } }); System.out.println(words.count()); } }
|
count() 할수를 호출했을 때 비로소 file 내용을 읽고 filter() 연산을 실제로 수행한다.
take() 나 collect() 함수도 있다. 다만 아주 큰 데이터에서는 collect() 사용을 자제하는 것이 좋다.
이유는 이를 단일 장비의 memory 로 내리는 역할을 하기 때문에 성능이 느려질 수 있다.
결과를 파일로 작성하고자 할 때에는 saveAsTextFile() 를 이용하면 된다.
Spark 의 Lazy Evaluation 은 RDD operation 중 Transformation 함수가 호출 되었을 때 실제로 동작하지 않음을 의미한다. 즉, Action Operation 이 호출될 때까지 실제로 파일을 읽어서 데이터 셋을 만들어 내지 않음을 의미한다. 이는 Hadoop 의 Map&Reduce 에서 operation 을 단순화 하기 위한 작업과는 대조적이다. Lazy Evaluation 특징으로 인해 Spark 는 간단한 operation 을 여러 번 사용하면서도 성능 이슈는 생각할 필요가 없게 되었다.
일반적으로 사용되는 RDD operation 에 대해서 좀 더 알아보고자 한다면 아래 Spark 공식 가이드 문서를 참고하자.
|
[참고사항]
distinct() 함수는 비용이 비한 Operation 이다. intersection(), substract() 또한 비싼 함수이다.
그 이유는 내부적으로 네트웍 상에서 데이터 shuffling 이 필요하기 때문이다.
|
RDD 는 기본적으로 Action operation 을 호출하기 이전까지는 별도의 작업을 하지 않는다고 설명하였다. 때에 따라서는 중간 RDD 를 재사용하고 싶을 때가 있을 것이다. 이 때 사용할 수 있는 것이 persist() 이다. cache() 함수와 유사한 동작을 한다. 아래 spark 공식 가이드 문서를 참고하자.
persist() 시에 StorageLevel 을 지정할 수 있다. 각 level 에 대한 용도를 확인하자.
'BigData > Spark' 카테고리의 다른 글
| Spark Memory Config on Apache YARN (0) | 2015.07.15 |
|---|---|
| Learning Spark Chapter. 4 Key/Value Pairs 사용하기 (0) | 2015.07.03 |
| Learning Spark Chapter. 2 스파크 설치 및 무작정 시작하기 (2) | 2015.07.03 |
| Learning Spark Chapter. 1 스파크를 이용한 데이터 분석 (0) | 2015.07.03 |
| Spark App 수행시 memory 이슈 (0) | 2015.05.22 |