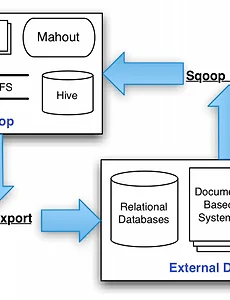
Apache Sqoop2 Sqoop 을 이용하여 Oracle에서 HDFS로 데이터를 전송할 때 Hdfs내에 파일명 지정이 가능할까? Sqoop2 를 이용해서 Oracle to HDFS 로 데이터를 전송할 때, HDFS 파일이 생성된다. 이 때 파일명은 sequene 하게 만들어지는 듯 한데. 이를 원하는 파일명 하나로 생성할 수 있을까? 일단 Job을 하나 생성해서 돌려보면 아래와 같이 파일이 생성된다. (아래 예제는 uMON WKLOG_USER 테이블의 하루치 데이터를 옮긴 것이다.) sqoop-connector-hdfs 컴포넌트에서 관련 코드를 확인이 가능하다. HdfsConnector 관련 클래스는 위와 같다. 실제로 HdfsWriter 클래스들이 HDFS 파일을 쓰게되며, 그 filename은 HdfsLoader에서 결정한다. 코드를 상세히 살펴보자. HdfsTestWriter @Override public void initi.. 2015. 4. 28. Sqoop의 개념 Sqoop이란? Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases. Apache Sqoop은 SQL-to-Hadoop 의 약자로 Apache Hadoop과 정형화된 Datasource, 예를 들어, Oracle 같은 RDB 간의 대량 데이터를 전송하기 위해 만들어진 툴이다. Oracle DB에 저장된 대량의 데이터를 HDFS 로 옮겨 분석을 하고자 할 때 쉽게 데이터를 Import 할 수 있으며, 반대로 분석 결과(HDFS)를 RDB로 Export 할 수 있다. 또한 Hive, Pig, Hba.. 2015. 4. 10. 이전 1 다음