Hadoop이란?
MapReduce + HDFS + (YARN)
HDFS 데이터 블록 크기 = 128MB
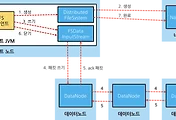
HDFS 구성요소
- Namenode: 데이터 블록의 위치를 저장
- Secondary Namenode: HDFS 파일시스템 이미지 및 Edit Log 병합
- DataNode: 데이터 블록 저장
데이터 읽기

데이터 쓰기

첨부
 하둡완벽가이드_3장_HDFS.pdf
하둡완벽가이드_3장_HDFS.pdf'BigData > Hadoop' 카테고리의 다른 글
| HDFS에 파일을 저장할 때, 데이터 노드 장애로 Replication을 모두 저장하지 못한 경우 (0) | 2017.04.24 |
|---|---|
| HDFS 네임노드에서 metadata size 한계는 어떻게 될까? (0) | 2017.04.24 |
| Hadoop shell 사용법 (0) | 2016.02.10 |
| Hadoop 에서 작은 크기의 파일을 처리하는 방법 (0) | 2016.02.10 |
| HDFS 내에 여러 파일을 하나의 파일로 합쳐보기 (0) | 2015.05.21 |