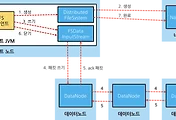
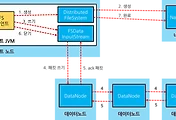
HDFS에서 각 파일들은 블록(128MB) 단위로 나눠져 여러 데이터노드에 저장된다.(복제본 포함)
이 때 네임노드는 각 블록들의 위치 정보(metadata)를 메모리에 저장하게 되고 클라이언트가 특정 파일을 읽을 때, 블록들의 위치 정보를 알려주게 되어 있다.
|
FsImage와 EditLog
네임노드에서 FsImage나 EditLog에 기록을 파일로 남기고 있으나, 메모리에 유지한 정보만 서비스한다.
네임노드가 시작될 때, FsImage와 EditLog를 읽어서 메타 정보를 구성하게 되며, 이 때 데이터노드로부터 정보를 받기도 한다. Secondary Namenode가 정상 동작하지 않는 경우 EditLog가 커질 수 있어 네임노드 구동시 많은 메모리와 시간이 소요될 수 있다.
|
위에서 네임노드에 대해서 간단히 정리해 보았다. 상세한 내용은 [하둡완벽가이드] 3장 HDFS(http://tomining.tistory.com/181)를 참고하자.
질문: 네임노드는 블록들의 메타 정보를 메모리에 저장하고 있다고 설명하였다. 그렇다면 블록들이 너무 많아서 네임노드의 메모리 사이즈를 넘어가면 어떻게 될까?
답변: 하둡 공식 문서(https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes)에서는 네임노드 메모리 Limit에 대한 별도의 언급은 존재하지 않는다.
The Persistence of File System MetadataThe HDFS namespace is stored by the NameNode. The NameNode uses a transaction log called the EditLog to persistently record every change that occurs to file system metadata. For example, creating a new file in HDFS causes the NameNode to insert a record into the EditLog indicating this. Similarly, changing the replication factor of a file causes a new record to be inserted into the EditLog. The NameNode uses a file in its local host OS file system to store the EditLog. The entire file system namespace, including the mapping of blocks to files and file system properties, is stored in a file called the FsImage. The FsImage is stored as a file in the NameNode’s local file system too.
The NameNode keeps an image of the entire file system namespace and file Blockmap in memory. This key metadata item is designed to be compact, such that a NameNode with 4 GB of RAM is plenty to support a huge number of files and directories. When the NameNode starts up, it reads the FsImage and EditLog from disk, applies all the transactions from the EditLog to the in-memory representation of the FsImage, and flushes out this new version into a new FsImage on disk. It can then truncate the old EditLog because its transactions have been applied to the persistent FsImage. This process is called a checkpoint. In the current implementation, a checkpoint only occurs when the NameNode starts up. Work is in progress to support periodic checkpointing in the near future.
The DataNode stores HDFS data in files in its local file system. The DataNode has no knowledge about HDFS files. It stores each block of HDFS data in a separate file in its local file system. The DataNode does not create all files in the same directory. Instead, it uses a heuristic to determine the optimal number of files per directory and creates subdirectories appropriately. It is not optimal to create all local files in the same directory because the local file system might not be able to efficiently support a huge number of files in a single directory. When a DataNode starts up, it scans through its local file system, generates a list of all HDFS data blocks that correspond to each of these local files and sends this report to the NameNode: this is the Blockreport.
|
CDH 공식문서(https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_nn_memory_config.html)에서도 많은 양의 정보를 저장할 수 있다 정도로 언급하고 있을 뿐 메모리를 넘어설 경우를 소개하고 있지 않다.
Disk Space versus Namespace
The CDH default block size (dfs.blocksize) is set to 128 MB. Each namespace object on the NameNode consumes approximately 150 bytes.
On DataNodes, data files are measured by disk space consumed—the actual data length—and not necessarily the full block size. For example, a file that is 192 MB consumes 192 MB of disk space and not some integral multiple of the block size. Using the default block size of 128 MB, a file of 192 MB is split into two block files, one 128 MB file and one 64 MB file. On the NameNode, namespace objects are measured by the number of files and blocks. The same 192 MB file is represented by three namespace objects (1 file inode + 2 blocks) and consumes approximately 450 bytes of memory.
Large files split into fewer blocks generally consume less memory than small files that generate many blocks. One data file of 128 MB is represented by two namespace objects on the NameNode (1 file inode + 1 block) and consumes approximately 300 bytes of memory. By contrast, 128 files of 1 MB each are represented by 256 namespace objects (128 file inodes + 128 blocks) and consume approximately 38,400 bytes. The optimal split size, then, is some integral multiple of the block size, for memory management as well as data locality optimization.
By default, Cloudera Manager allocates a maximum heap space of 1 GB for every million blocks (but never less than 1 GB). How much memory you actually need depends on your workload, especially on the number of files, directories, and blocks generated in each namespace. If all of your files are split at the block size, you could allocate 1 GB for every million files. But given the historical average of 1.5 blocks per file (2 block objects), a more conservative estimate is 1 GB of memory for every million blocks.
Important: Cloudera recommends 1 GB of NameNode heap space per million blocks to account for the namespace objects, necessary bookkeeping data structures, and the remote procedure call (RPC) workload. In practice, your heap requirements will likely be less than this conservative estimate.
|
네임노드의 1GB 메모리로 최대 100만개의 블록 정보를 할당한다라고 언급하고 있다. 그리고 마지막에서 "실제 메모리 사용량은 추정치보다 작을 것이다”라고 언급하고 있다.
CDH의 추정치를 확인해보자.
Example 2: Estimating NameNode Heap Memory Needed
In this example, memory is estimated by considering the capacity of a cluster. Values are rounded. Both clusters physically store 4800 TB, or approximately 36 million block files (at the default block size). Replication determines how many namespace blocks represent these block files.
Cluster A: 200 hosts of 24 TB each = 4800 TB.
At capacity, with the recommended allocation of 1 GB of memory per million blocks, Cluster A needs 36 GB of maximum heap space.
Cluster B: 200 hosts of 24 TB each = 4800 TB.
At capacity, with the recommended allocation of 1 GB of memory per million blocks, Cluster B needs 12 GB of maximum heap space.
Both Cluster A and Cluster B store the same number of block files. In Cluster A, however, each block file is unique and represented by one block on the NameNode; in Cluster B, only one-third are unique and two-thirds are replicas.
|
"복제본을 3개 유지하더라도 4800TB를 관리하는데, 12GB의 메모리면 가능하다"라고 되어 있다. 아마도 네임노드의 힙 메모리 크기는 크게 신경 쓰지 않는 것 같다. 만약 PB급 데이터를 관리해야 한다면 Federation 기능을 통해서 네임노드를 분리해야 하지 않을까 생각한다.
Hortonworks 공식문서(https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.4.2/bk_installing_manually_book/content/ref-80953924-1cbf-4655-9953-1e744290a6c3.1.html)에서도 네임노드 메모리 설정에 대해서 아래와 같이 가이드하고 있다.

참고
- http://itm-vm.shidler.hawaii.edu/HDFS/ArchDocCommunication.html
- https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
- https://www.cloudera.com/documentation/enterprise/5-8-x/topics/admin_nn_memory_config.html
- https://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.4.2/bk_installing_manually_book/content/ref-80953924-1cbf-4655-9953-1e744290a6c3.1.html
'BigData > Hadoop' 카테고리의 다른 글
| mapreduce.task.io.sort.mb 옵션이란? (0) | 2017.05.18 |
|---|---|
| HDFS에 파일을 저장할 때, 데이터 노드 장애로 Replication을 모두 저장하지 못한 경우 (0) | 2017.04.24 |
| [하둡완벽가이드] 3장 HDFS (0) | 2017.04.19 |
| Hadoop shell 사용법 (0) | 2016.02.10 |
| Hadoop 에서 작은 크기의 파일을 처리하는 방법 (0) | 2016.02.10 |