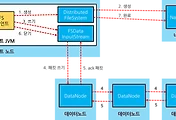
Hadoop 은 기본적으로 Input 파일 갯수만큼 Map Task 가 생성된다. 만약 작은 파일이 엄청 많다면? Block Size 이하의 파일들이 많은 경우는?
block size(64MB) 보다 작은 파일이 여러 개 더라도 Map Task 는 파일 당 하나씩 생성된다.
그렇다면 어떻게 처리하는 것이 좋을까?
위 블로그에 잘 정리되어 있다.
결론만 정리해보면 아래와 같다.
- hdfs 에 저장할 때, 파일 내용을 append 하는 방법
- 작은 파일들을 하나로 합치는 작업을 주기적으로 실행하는 방법
- hadoop archive (har) 파일을 이용하는 방법
- 파일 이름과 파일 내용을 각각 키와 값으로 해서 sequence file 로 저장하는 방법
- CombineFileInputFormat 을 이용해서 맵 리듀스 작업을 수행하는 방법
- HBase 에 데이터를 저장하는 방법
'BigData > Hadoop' 카테고리의 다른 글
| HDFS 네임노드에서 metadata size 한계는 어떻게 될까? (0) | 2017.04.24 |
|---|---|
| [하둡완벽가이드] 3장 HDFS (0) | 2017.04.19 |
| Hadoop shell 사용법 (0) | 2016.02.10 |
| HDFS 내에 여러 파일을 하나의 파일로 합쳐보기 (0) | 2015.05.21 |
| HDFS 내에 있는 파일에 Append 하기 (0) | 2015.05.20 |