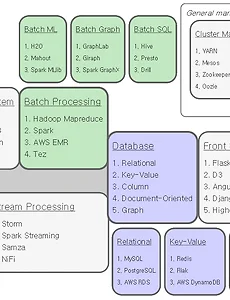
bigdata3 거리(distance) 구하기 네이버 블로그에서 퍼 온 글입니다. 유클리드 거리 (Euclidean distance) 표준화 거리 (statistical distance) , D = 마할라노비스 (Mahalanobis) 거리 , S = 체비셰프 (Chebychev) 거리 맨하탄 (Manhattan) 거리 맨하탄 거리는 바둑판 처럼 가로,세로 길이를 더한 것이라 한다. ("데이터마이닝", 방통대) 직선길이가 아닌 캔버라 (Canberra) 거리 민코우스키 (Minkowski) 거리 여기서부터는 유명한 거리들 몇 개에 대한 설명 마할라노비스 거리는 분산을 고려한 거리이다.왜 분산을 고려하냐면 , 분산이 클 경우 점들이 더 멀리 퍼져있을 거란 가정 때문이다. 위의 오른쪽 그림에서분산을 고려하지 않을 경우 점1 과 점2의 거리(유클리디안 거.. 2015. 3. 16. The Data Engineering Ecosystem: An Interactive Map http://insightdataengineering.com/blog/The-Data-Engineering-Ecosystem-An-Interactive-Map.html 데이터 수집, 배치 처리, 스트림 처리, 프론트 엔드까지 각 영역별로 어떤 대안들이 있는지 한눈에 들어오도록 잘 정리한 맵입니다. http://insightdataengineering.com/blog/pipeline_map.html 에서 각 카테고리별로 간단한 설명을 확인할 수 있습니다.(카테고리들에 마우스를 가져가 보세요.) 아래 내용은 위 URL 내용을 번역한 내용입니다. Companies, non-profit organizations, and governments are all starting to realize the huge va.. 2015. 3. 12. Apache Storm 무작정 따라하기 Maven Project 생성 pom.xml 설정 4.0.0 com.jw.storm hellostorm 0.0.1-SNAPSHOT jar hellostorm http://maven.apache.org UTF-8 junit junit 3.8.1 test org.apache.storm storm-core 0.9.3 maven-assembly-plugin 2.2.1 jar-with-dependencies make-assembly package single 구조 Spout에서 Bolt로 "hello storm"이라는 메시지를 전송한다. 실제 클러스터 환경에서는 spout은 외부로부터 데이터를 받아서 가공 후 bolt로 전송해 주는 식으로 적용될 것이다. 여기서 spout과 bolt를 연결해 주는 Topology.. 2015. 3. 6. 이전 1 다음