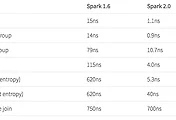
Spark 에서 Schema 를 지정해 Dataframe 을 생성한다면 좋겠지만 csv 등 schemaless 하게 Dataframe 을 생성한 경우 타입을 변경해야 할 일이 있을 수 있다.
기본적으로 아래와 같이 캐스팅 하면 된다.
df.withColumn(columnName, col(columnName).cast("type"))
만약 변경해야 하는 컬럼이 여러 개라면?
import org.apache.spark.sql.DataFrame
import org.apache.spark.sql.functions._
val DEFAULT_COLUMN_TYPES_MAP =
Map(
"SEQ" -> "decimal(9,0)",
"AMT" -> "decimal(9,0)"
)
object DataFrameExtensions extends Serializable {
implicit class DataFrameExtension(df: DataFrame) extends Serializable {
def applyColumnType(columnTypeMap: Map[String, String] = DEFAULT_COLUMN_TYPES_MAP): DataFrame = {
var temp = df
for (columnName <- df.columns) {
val typeName = columnTypeMap.collectFirst {
case tp if columnName.contains(tp._1) => tp._2
}.getOrElse("string")
// println(s"convert $columnName -> $typeName")
temp = temp.withColumn(columnName, col(columnName).cast(typeName))
// df.printSchema()
}
return temp
}
}
}
import DataFrameExtensions._위 예제는 DEFAULT_COLUMN_TYPES_MAP 에 컬럼명 패턴을 등록하고 일괄로 타입을 변경하는 코드다.
만약 특정 컬럼명을 full 로 작성한 경우라면 확장함수 내에 컬럼명 비교 구문을 equals 로 변경하면 된다.
columnName == tp._1위처럼 구현 후 사용은 아래와 같이 해 줄 수 있다.
df.applyColumnType().printSchema()
만약 확장함수가 실행이 되지 않는다면... 확장함수 생성 후 import 로 활성화 해 주었는지 체크하자.
Dataframe 을 정의된 스키마로 읽을 수 있는 방법은 간단히 해 볼 수 있다.
'BigData > Spark' 카테고리의 다른 글
| Spark Memory Tuning Case-Study (0) | 2024.04.14 |
|---|---|
| Spark Streaming Resiliency(자동복구) (2) | 2016.05.15 |
| Spark 2.0 Technical Preview (0) | 2016.05.15 |
| Learning Spark Chapter. 10 Spark Streaming (0) | 2015.08.20 |
| Learning Spark Chapter. 9 Spark SQL (0) | 2015.07.31 |