데이터 과학자의 가설 사고 3장을 읽고 정리해 본 내용이다.
3장에서는 데이터를 설명하는 방법에 대해서 소개를 한다. 데이터 설명을 위해서 수치를 시각화하고 비교하는 연습이 필요하다.
시각화
데이터를 시각화 하는 방법은 너무나도 다양하다. 시각화 영역만을 다루는 업무가 있을 정도로 전문적인 영역이며, 데이터 패턴, 특징, 경향을 파악하는데에도 큰 도움을 줄 뿐만 아니라 데이터를 보는 사람에게 강력한 첫인상을 남기기도 하고 때로는 심각한 편향을 일으키기도 한다.
(책에서 소개하고 있는) 막대 그래프, 꺽은선 그래프, 산포도, 원 그래프는 시각화를 잘 모르는 사람들도 주변에서 많이 보았을 것이다. 아주 기본적인 그래프라서 따로 설명하지 않으려고 한다. (궁금한 사람은 구글에 검색만 해 봐도 많은 이미지들이 나올 것이다)
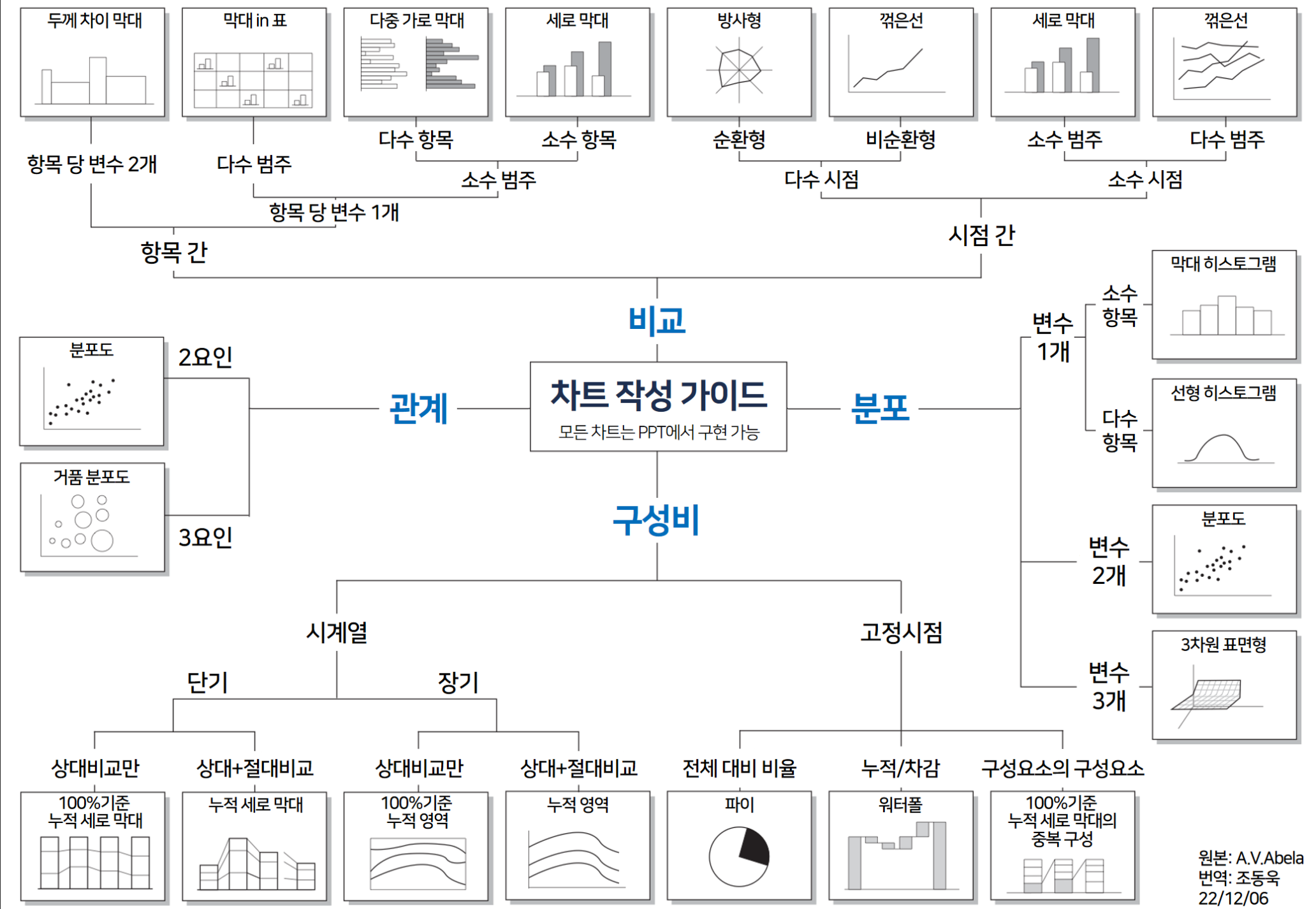
어떤 차트를 선택할 지는 정답이 없다. 데이터에서 발견한 의미를 적절하고 명확히 전달할 수 있는 시각화 방식이 필요할 뿐이다. 위 그림은 크게 4가지 Factor 로 구분하여 차트를 제안하고 있다. 오래된 자료이기도 하고 시각화 또한 트랜드도 많이 변했고 샘플 또한 다양해졌다.
시각화 도구인 Tableau 에서 유명한 10가지 시각화 방식을 소개하고 있다.

정확히 어떻게 읽고 분석해야 하는지 잘 모르지만 1812년 나폴레옹이 모스크바 점령을 위해 47만 병사를 이끌고 출발해 1만만 돌아온 과정을 시각화 한 것이라고 한다. 역사상 유명한 시각화 사례라고 한다. (개인적으로 어떻게 읽고 해석해야 하는지 잘 모르겠다)

1850년대 크림전쟁에서 군인들의 사망원인을 분석해 시각화 한 자료로, 간호사였던 Florence Nightingale (나이팅게일) 이 시각화를 통해서 대부분의 사망원인이 열악한 병원 상태에서 기인한다는 것을 밝혀낸 사례이다. 나선형 차트의 어두운 부분이 총 사망 수를 나타내고, 더 어두운 부분이 전투에서 사망한 경우를 나타낸다. 차트만 봐도 사망한 군인 대부분이 전투에서 사망한 것이 아님을 알 수 있다.
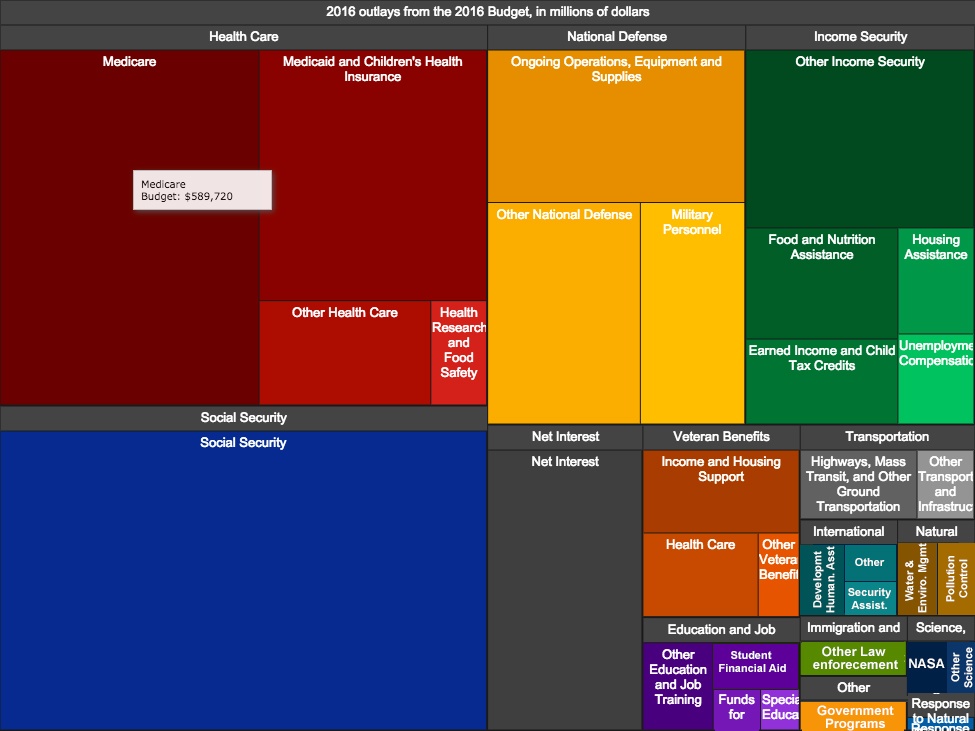
2016년 오바마 행정부의 예산 집행 영역을 비율로 나타낸 차트이다. 국가 예산을 Social Security(사회보장), Medicare(의료), Medicaid and Children's Health Insurance (저소득층 보험 지원) 순으로 많이 할당한 것을 한 눈에 볼 수 있다. (왜 오바마케어라는 이야기가 나왔는지 알 수 있는 대목이다)
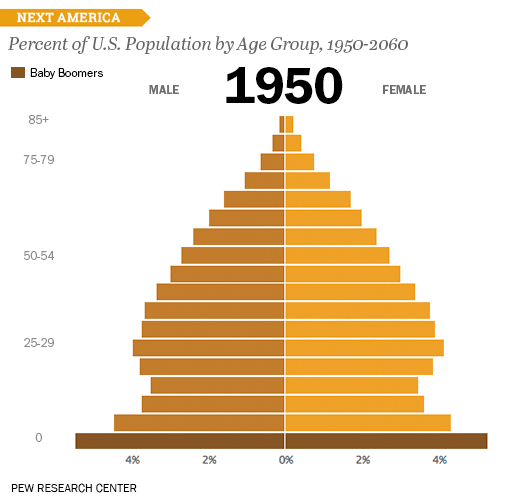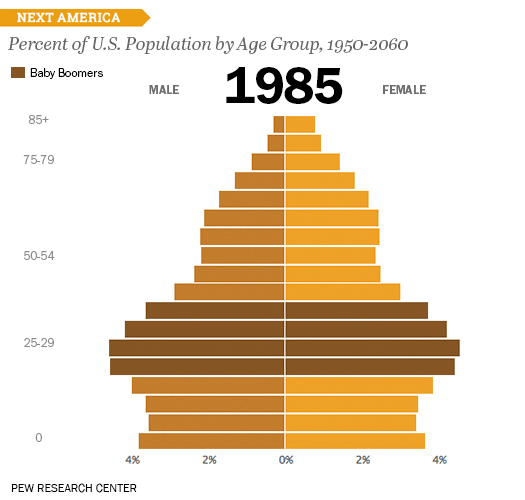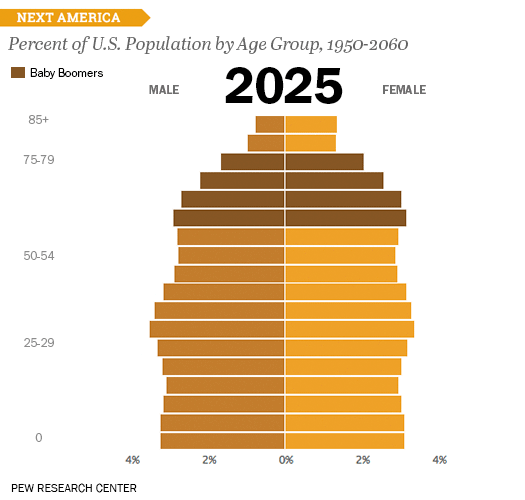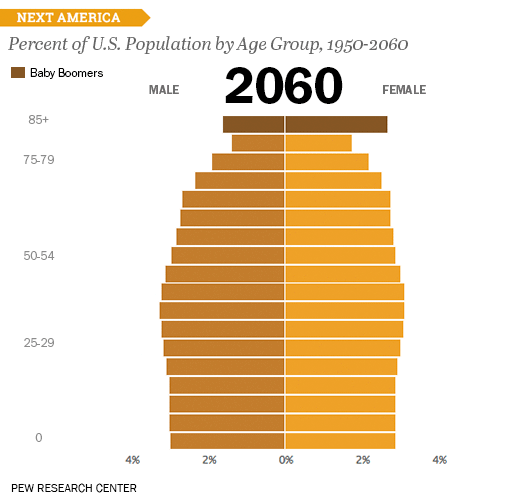
1950 ~ 2060년까지 연령별 성별 비율을 보여주는 차트이다. 우리나라에서도 인구 비중을 소개할 때 많이 활용하는 차트이다. 젊은 층이 줄고 노년층이 늘어나는 것을 알 수 있고, 나이가 올라갈 수록 여성 비율이 더 높은 것을 볼 수 있다. (흔히 여자가 남자보다 장수한다는 것을 보여준다)
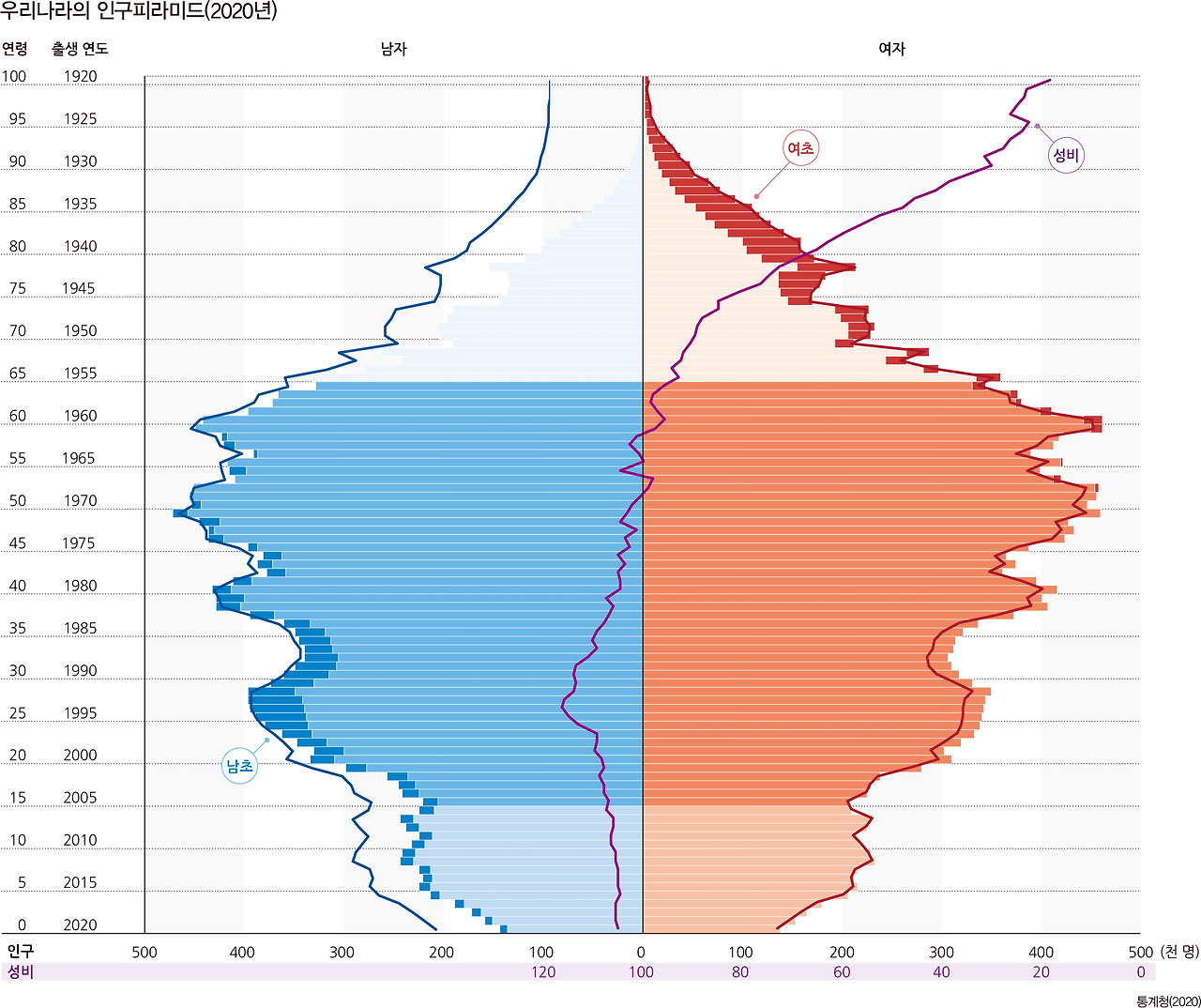
2020년 대한민국 인구 피라미드이다. 경제활동이 가능한 20~60세까지 전체인구의 중심을 이루고 있으나, 최근에는 젊은층이 좀 더 얇아졌다. 좀 더 상세한 데이터는 통계청 사이트에 가면 많은 정보를 확인할 수 있다. (Open-api 로도 제공한다)
시각화의 왜곡
글을 시작할 때에도 잠시 언급했지만, 시각화는 양날의 검이다. 데이터의 패턴, 경향처럼 걍렬한 인사이트를 아주 쉽게 전달할수도 있지만 잘못된 인상을 심어줄 수도 있다. 아래 사례는 데이터 시각화 101에서 데이터 속 거짓말 발견하기에 나오는 내용이다.

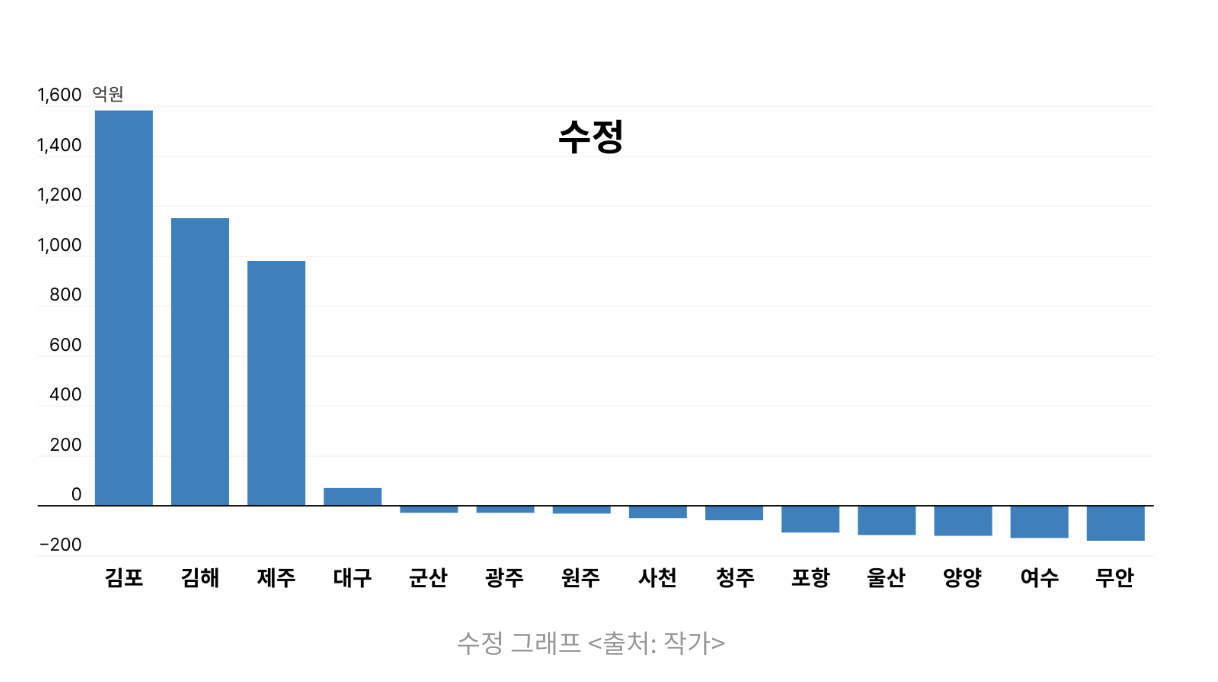




좌측은 기사에 인용된 차트이고 우측은 실제 데이터를 기반으로 보정한 차트이다. 어떤가? 지방공항 위기를 언급하며 소개한 차트를 보면 마치 주요 공항의 이익만큼 지방공항은 손실을 보고 있는 것처럼 보이나 사실은 단위가 다르다. 애플 아이폰 매출의 경우는 누적 매출로 매출이 급상승하는 것처럼 소개했고, 마지막 미국지도 차트는 붉은색이 공화당 지지도라고 한다. 시각화를 어떻게 하느냐에 따라 데이터를 명확하게 보여 줄 수도 왜곡 할 수도 있다. 이런 부분은 차트를 만들어 낼 때도 만들어진 차트를 볼 때에도 주의해야 한다.
데이터 비교
하나의 데이터만으로는 보통 인사이트를 얻기 어렵다. 유사한 것과 비교하고, 가정치 (또는 계획치) 와 실측치를 비교하고, 또는 잘된 것과 못된 것을 비교함으로서 개선에 대한 해결책을 찾는 등 비교야 말로 여러모로 꼭 필요한 작업이다. 그럼 어떻게 비교해야 할까?
적절한 비교 대상 설정
Apple to Apple, Apple to Orange 라고 책에서는 용어를 소개한다. (용어보다는) 야구를 생각하면 투수와 타자를 비교하면 의미가 있을까? 타자 중에서도 1번 타자, 4번타자, 9번타자를 비교하는 것이 의미가 있을까? (참고로 보통 1번은 출루율이 높은 타자, 4번은 장타율이 높은 타자, 9번은 수비가 중요한 유격수 or 2루수가 맡는다) 유사한 대상과 비교를 해야한다.
데이터를 비교하는 4가지 시점
- 어떤 시점과의 비교: 기준이 되는 시점으로부터의 변환 (변화율, 성장률) -> 기업 매출 공시를 보면 이전 쿼터와 비교, 전년도 동쿼터 비교 등 비교 시점에 따라 결과가 달라지기도 한다. 시점이 주는 특수성이 있기 때문이다.
- 계획값과의 비교: 계획값에 대한 실적 달성 정도 (달성률) -> 연초에 예산안을 계획하고 연말에 계획안과 비교, 과제 KPI 를 설정하고 마지막에 결과물을 보고 KPI 달성 여부를 확인
- 타자와의 비교: 성질이 같은 것끼리의 차이(우열, 간격) -> 위에서 언급한 내용. (야구에서) 김광현, 양현종을 많이 비교한다. 우리나라 대표하는 좌완 투수이다. (류현진도 있지만 메이저리그를 평정한 선수로 두 선수보다는 한등급 위인 것 같다)
- 전체와의 비교: 전체 대비 구성비 (공헌도, 영향도, 점유율) -> 농심 신라면과 오뚜기 진라면 점유율
데이터 분해
매출 데이터를 분석할 때에는 고객 수와 고객 단가로 나눠서 살펴볼 수 있다. 고객 수가 적다면 방문 촉진을 위한 활동을 고객 단가가 낮다면 Upselling 이나 Cross-Selling 을 검토해야 하는 것처럼 다른 결론이 날 수 있다. OTT 서비스에서도 신규 유저와 기존 유저는 다르게 바라본다. 매주 (또는 매일/매월) 신규 유저가 적절히 있으나 기존 유저가 낮다면 리텐션을 위해 기존 유저가 이탈하지 않는 방법을 고민해야 한다. 또는 반대로 기존 유저는 일정 수준 유지되나 신규 유저가 너무 없다면 이벤트나 프로모션을 고려해 볼 수 있을 것이다. (첫달 무료 같은 경우가 보통 신규 유저를 대상으로 하는 홍보활동이다)
- 곱셈에 의한 분해
- 덧셈에 의한 분해
데이터에서 과제 도출
데이터를 시각화하고 비교를 한 이유는 무엇일까? 현재 문제점을 찾아내고 더 나은 방안을 도출하고자 함이다.
- 데이터 집계값을 확인하자.
- 데이터를 시각화하고, 특이점이나 경향성, 상이성을 찾자.
- 복수의 데이터를 조합해 관련성을 찾자.
- 데이터에서 얻은 내용을 정리해 해결 방안을 검토하자.
책에서는 위와 같은 순서로 소개하고 있으나, EDA 를 하는 과정은 이처럼 단순한 과정은 아니다. 직접 해 보면 상단히 고단하고 단순한 작업들이 많으며, 뭔가 번쩍이는 아이디어가 떠 올라 해결할 수 있는 작업은 아니다. 인내심을 가지고 차근차근 데이터를 들여다 보아야 한다. 경험상 사소한 곳에도 호기심을 가진다면 좋은 분석을 할 수 있을 때가 많았다. (관심이 있는 분야는 좀 더 편하고 쉽게 다가오는 것처럼 말이다)
'BigData > Data Science' 카테고리의 다른 글
| 데이터 리터러시 #5 (0) | 2024.05.09 |
|---|---|
| 데이터 리터러시 #4 (0) | 2024.04.27 |
| 데이터 리터러시 #2 (0) | 2024.04.24 |
| 데이터 리터러시 #1 (0) | 2024.04.17 |
| R과 Shiny 를 이용한 데이터 제품 만들기 (0) | 2016.02.26 |



