Inflearn에서 NLP 강좌인 "예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지" 강좌를 들으며 정리한 글입니다. 섹션3까지는 사전 준비 과정이라 별도로 정리하지 않았습니다.
NLP 문제영역
- Machine Translation: 기계 번역, 파파고 같은 언어 번역
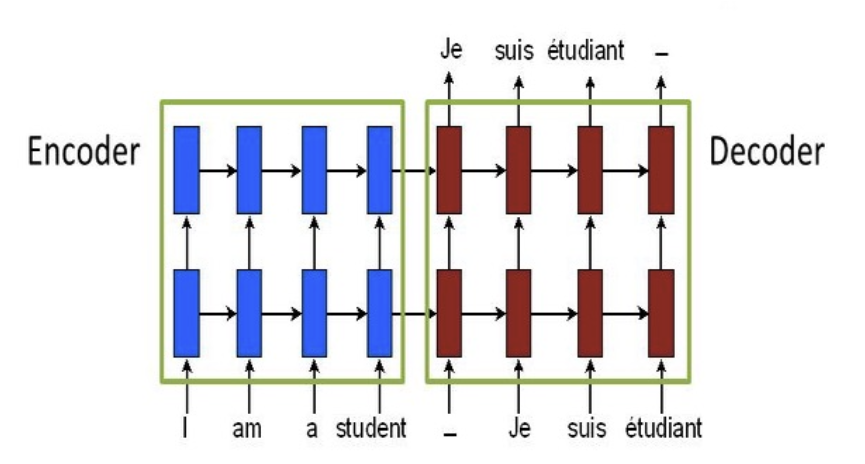
- Sentiment Analysis: 문장의 감정상태를 분석

- 영화 리뷰 코메트를 보고 긍정/부정 구분
- Spam Filtering

- 스패머도 고도화 되어 창과 방패의 싸움에 NLP가 활용
- Image Captioning
- Text Summarization: 내용 요약
- 🌟 Question Answering

- 고객상담 봇에 활용
- Dialogue Generation
딥러닝 모델로 진화
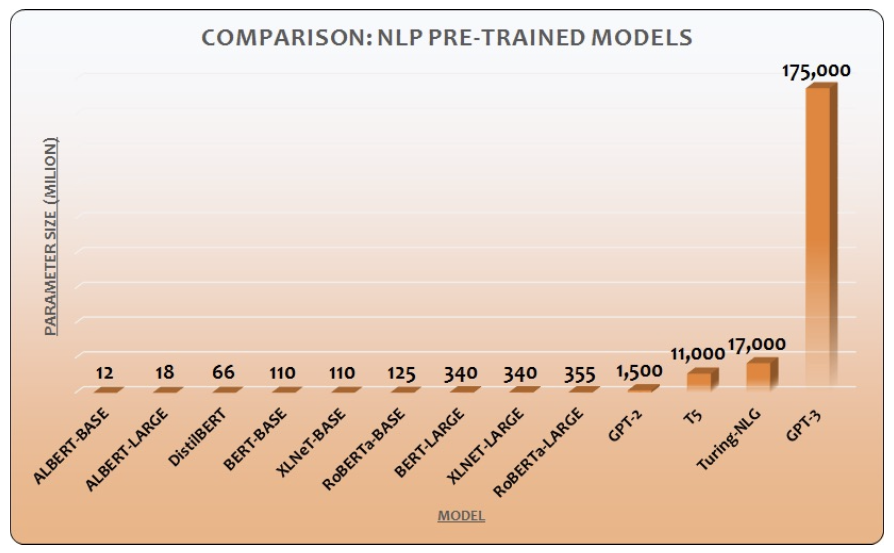
- (2020년 기준)
- 이때 BERT와 GPT가 시작된 초반 인 듯
- 현재는 GPT-4o 까지 나옴
- GPT-5 는 아직 공개되지 않음 (2024-07-16기준)
Pre-trained => Fine-Tuning

NLP 용어
- Corpus: NLP에서 다루는 데이터 셋
- Token: 분석하고자 하는 단위로 나눈 것, 문장에서 형태소까지 다양
- 한글의 경우 초성, 중성 등을 나눠서 Tokenize 하기도 함
- Vocabulary Set: 처리하는 문제 영역의 전체 단어 집합
- Set에 포함되지 않은 단어들은 <UNK> 로 특수 토큰처리
- <s>, <|s>, <pad> 등 다양.



