WordCount 로직을 구현해보자.
Java로 구현하더라도 함수형 언어 코딩 개념이 필요하다.(java8을 경험해봤다면 좀 더 쉽게 이해할 수 있을 것이다.)
public void executeSparkTask(String sourceFilePath, String outputFilePath) throws Exception { |
public static void main(String[] args) throws Exception { |
위처럼 구현했다.
순서대로 로직을 좀 살펴보면,
1. 파일 내용을 읽어서 Iterable이 가능한 Collection 객체로 만든다.
2. Tuple2 객체를 이용하여 Key, Value 형태로 Mapping을 한다.
3. Reduce 를 통해 Key, Count 형식의 데이터가 된다.
기본적인 Map&Reduce 로직가 차이가 없다.
수행해보자.
| $ ~/apps/spark/bin/spark-submit --class "com.nhncorp.umon.spark.app.SampleApp" --master yarn-cluster --num-executors 1 hdfs://dev-umn-udm001.ncl:9000/umon-udm-1.0.0.jar |

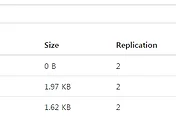
Output 이 위 화면처럼 생성되었음을 확인할 수 있다.
여기서 part-00000 과 part-00001 두 개로 output이 생성된 이유는 spark cluster 로 구성되어 있어, worker 2개에서 병렬로 처리되었기 때문이다.
병렬로 처리된 경우 병목현상을 방지하기 위해서 output 도 따로 생성하는 듯 하다.
이는 추축이며, 추후에 spark code를 분석해 보도록 하자.
'BigData > Spark' 카테고리의 다른 글
| Spark App 수행시 memory 이슈 (0) | 2015.05.22 |
|---|---|
| Spark로 WordCount 구현하기. #2 (0) | 2015.05.21 |
| Apache Spark: Transformations 샘플 (0) | 2015.03.17 |
| Apache Spark 1.2.0은 Netty기반과 고가용성, 머신러닝 API를 지원한다. (0) | 2015.03.06 |
| 001. Spark를 설치해서 무작정 돌려보자. (2) | 2015.03.05 |