스파크는 scala 로 구현되어 있다. 따라서 JVM 환경에서 구동된다.
java 6 이상, python 2.6 이상 환경이 필요하다(단, python 3은 지원하지 않는다.)
일단 Apache Spark 를 다운로드 받아보자.
다운로드 받아서 tar 압축을 해제하면, 기본적인 설치는 끝난다.
물론 기본 설정만으로 spark-shell(뒤에서 자세히 알아본다.) 을 수행하는데는 문제가 없다.
tar -zxvf spark-1.4.0-bin-hadoop.2.6.tgz
여기서는 hadoop built-in 버전을 받았다. source code로 다운받아서 빌드해도 무방하다.
단, source code 로 빌드하려면 sbt 가 설치되어 있어야 한다.
압축 해제 후 내부 디렉토리를 살펴보면 아래와 같다.

디렉토리 구조를 좀 살펴보자.
- bin
spark-shell, spark-submit 등 spark 를 실행해 볼 수 있는 실행 파일을 포함한다. - sbin
spark process 를 구동(start-all.sh) 하는 파일을 포함한다. - conf
spark 설정파일을 포함한다.- spark-env.sh
- spark-default.properties
- log4j.properties
- R/ec2/python
- example
간단한 spark 예제들을 포함한다.
스파크는 scala 와 python shell 을 지원한다.
java 는 언어 특성상 interactive 환경을 지원하지 않으므로 spark-shell 을 사용할 수 없다.
여기서는 scala shell 을 샘플로 실행해 본다.
./bin/spark-shell

단순히 spark-shell 만 띄웠을 뿐인데, 상당히 많은 로그가 출력된다.
로그가 너무 많다면, conf/log4j.properties 파일을 수정하자. 처음이라면 log4j.properties.template 파일을 복사하여 설정하면 된다.
|
log4j.rootCategory=WARN, console
|
위 처럼 설정하면 장황한 로그는 생략되고 간단한 로그만 출력됨을 확인할 수 있다.
Spark 예제를 수행하기 전에 RDDs 라는 데이터 유형이 있는데,
RDDs 에 대해 추후에 자세히 알아보기로 하고, 여기서는 RDDs 라는 것이 있고, Spark에서 사용되는 추상 데이터임만 확인하고 넘어가자.
README.md 라는 파일로 RDDs 를 한 번 생성해보자.
README.md 라는 파일을 읽어서 lines 라는 RDDs 를 생성했다.

lines 라는 RDDs 의 갯수를 알아보자.
98 이라고 잘 출력됨을 확인 할 수 있다.(아래 캡쳐 화면 확인)

lines 라는 RDDs 의 첫번째 데이터는?

spark-shell 을 통해서 spark 를 간단히 수행해 보았다.
그렇다면 spark 가 내부적으로 어떻게 수행되는지 알아보자.

Driver Program 을 통해서 Spark Cluster 에 접속을 하게 된다.
spark-shell 은 기본적으로 제공되는 Driver Program 이라고 할 수 있다.
이 때 Spark Context 라는 것을 사용하게 되는데, spark-shell 의 경우는 Spark Context 를 자동적으로 생성해 주며, sc 라는 변수로 접근이 가능하다.
RDDs 의 operation 을 수행하면 Executor 라는 노드를 통해서 수행이 되는데, standalone 환경에서는 하나의 Executor 가 있다고 생각하면 된다.
Cluster 환경이 되면, 여러 개의 Executor Node 에서 병렬적으로 수행된다.
위에서 수행한 샘플 예제에서 count() 를 수행하면 Executor 가 할당 받은 파일의 일부분에 대해서 count() 를 수행하게 되고
Spark Context 가 결과들을 합쳐서 최종 결과물(count = 98) 을 만들어 내게 된다.
Standalone Application 을 작성해보자.
spark-shell 과의 차이점은 SparkContext 초기화를 해야 한다는 사실이다. 그 외에는 동일하다.
먼저 Maven dependency 설정이 아래와 같이 필요하다.
|
groupId = org.apache.spark
artifactId = spark-core_2.10
version = 1.4.0
|
Maven 외에도 scala 의 sbt 나 gradle 을 이용할 수 도 있다.
spark-core 가 준비되었다면, SparkContext 를 초기화 해보자.
|
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster(“local”).setAppName(“My App”)
sc. SparkContext(conf = conf)
|
|
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
var conf = new SparkConf().setMaster(“local”).setAppName(“My App”)
var sc = new SparkContext(conf)
|
|
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
SparkConf conf = new SparkConf().setMaster(“local”).setAppName(“My App”);
JavaSparkContext sc = new JavaSparkContext(conf);
|
master 를 local 로 지정한 것은 standalone 환경에서 수행하기 때문이다. 만약 cluster 환경이라면 master URI 정보를 주거나 Yarn/Mesos 를 줄 수도 있다.
AppName 의 경우는 cluster 환경에서 cluster UI 에서 해당 application 을 구분할 수 있는 이름을 의미한다.
위 처럼 SparkContext 를 초기화 했다면, Application을 종료 할 때 아래 방법을 사용할 수 있다.
|
sc.stop();
또는
System.exit(0); or sys.exit()
|
이처럼 Spark 는 python, scala, java 를 모두 이용할 수 있다.
Java로 가능한 기능은 scala나 python 으로 가능하기 때문에 예제는 java 로 소개한다.
단어 갯수를 세는 Application 을 작성해보자(WordCount)
|
package com.tomining.spark.tutorial.example;
import java.io.Serializable;
import java.util.Arrays;
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.FlatMapFunction; import org.apache.spark.api.java.function.Function2; import org.apache.spark.api.java.function.PairFunction; import scala.Tuple2; public class WordCount implements Serializable { public void execute(String inputPath, String outputFile) { SparkConf conf = new SparkConf().setMaster("local").setAppName("WordCount"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<String> input = sc.textFile(inputPath); JavaRDD<String> words = input.flatMap(new FlatMapFunction<String, String>() { public Iterable<String> call(String x) { return Arrays.asList(x.split(" ")); } }); JavaPairRDD<String, Integer> counts = words.mapToPair(new PairFunction<String, String, Integer>() { public Tuple2<String, Integer> call(String x) { return new Tuple2(x, 1); } }).reduceByKey(new Function2<Integer, Integer, Integer>() { public Integer call(Integer x, Integer y) throws Exception { return x + y; } }); counts.saveAsTextFile(outputFile); } }
|
|
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.tomining.spark</groupId> <artifactId>tutorial</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>tutorial</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.8.2</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.3.0</version> </dependency> </dependencies> <build> <pluginManagement> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.1</version> <configuration> <source>1.7</source> <target>1.7</target> </configuration> </plugin> </plugins> </pluginManagement> </build>
</project>
|
이를 Jar 로 빌드하여 아래와 같이 실행할 수 있다.
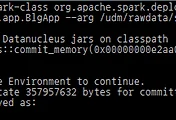
./bin/spark-submit —class com.tomining.spark.tutorial.example.WordCount ./target/.. ./README.md ./wordCounts
* spark-submit 말고도 spark-class 도 사용이 가능하다.
다만 상위버전에서는 deprecated 될 예정으로 spark-submit 을 사용하길 권장한다.
'BigData > Spark' 카테고리의 다른 글
| Learning Spark Chapter. 4 Key/Value Pairs 사용하기 (0) | 2015.07.03 |
|---|---|
| Learning Spark Chapter. 3 RDD 프로그래밍 (0) | 2015.07.03 |
| Learning Spark Chapter. 1 스파크를 이용한 데이터 분석 (0) | 2015.07.03 |
| Spark App 수행시 memory 이슈 (0) | 2015.05.22 |
| Spark로 WordCount 구현하기. #2 (0) | 2015.05.21 |