“하둡완벽가이드”의 6장 MapReduce 프로그래밍을 보면 샘플코드에서 mapreduce.task.io.sort.mb 옵션을 지정한다.(p.223)
처음 보는 옵션이라 어떤 역할을 하는 옵션일까?
Hadoop 공식 문서에서는 아래와 같이 설명하고 있다.
mapreduce.task.io.sort.mb
| 100
| The total amount of buffer memory to use while sorting files, in megabytes. By default, gives each merge stream 1MB, which should minimize seeks.
|
옵션 이름만 봐도 알 수 있듯이 buffer memory size이고 mb 단위로 설정한다. 기본값은 100mb로 되어 있다.
그렇다면 어떤 용도의 buffer memory일까?
Mapper나 Reducer는 output을 HDFS에 바로 작성하지 않는다.
memory에 일정 크기만큼 저장했다가 disk로 flush를 하는 구조이다. 이 때 mapreduce.task.io.sort.mb 설정한 메모리가 사용된다. 기본적으로 Hadoop block size는 128mb이니 128mb 데이터라면 100mb를 버퍼에 저장한 뒤 disk로 flush하고 나머지 28mb를 disk에 flush하는 방식이다.
그렇다면 적정치는 얼마일까? 그리고 얼마나 크게 설정할 수 있을까?
여러 문서를 찾아봐도 권장 설정 값은 찾을 수가 없었다. 다만 Mapper나 Reducer의 힙 메모리 크기보다 클 순 없는 듯 하다. stackoverflow에 검색 해 보면 어렵지 않게 오류 케이스를 확인 할 수 있다.
mapreduce.task.io.sort.mb 이 옵션의 최대값은 2047mb로 정해져 있다. 공식 문서에는 별다른 언급이 없으나 2047 이상으로 설정할 수 없는 버그가 있다.
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException("Invalid \"mapreduce.task.mapreduce.task.io.sort.mb\": " + sortmb);
}
|
mapreduce.task.io.sort.mb 이 옵션은 MapReduce의 성능 튜닝 포인트이며, 적당히 잘 조절하면 이득을 볼 수 있을 것이다.
나중에 테스트 환경을 만들어 테스트를 해 봐야겠다.
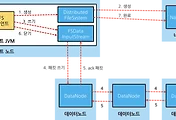
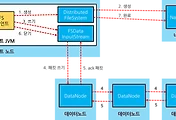
아래 다이어그램은 Map Task shuffle 순서를 잘 설명하고 있는 것 같다.

참고
- https://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
- http://tkyoo.tistory.com/41
- http://stackoverflow.com/questions/23422056/what-is-the-maximum-value-for-mapreduce-task-io-sort-mb
- http://docs.hortonworks.com/HDPDocuments/HDP2/HDP-2.1.3/bk_releasenotes_hdp_2.1/content/ch_relnotes-hdpch_relnotes-hdp-2.1.1-knownissues-mapreduce.html
- https://github.com/apache/hadoop-mapreduce/blob/HDFS-641/src/java/org/apache/hadoop/mapred/MapTask.java?source=cc#L746
- http://ercoppa.github.io/HadoopInternals/MapTask.html
'BigData > Hadoop' 카테고리의 다른 글
| Hadoop Safe-Mode란? (0) | 2017.06.15 |
|---|---|
| HDFS에 파일을 저장할 때, 데이터 노드 장애로 Replication을 모두 저장하지 못한 경우 (0) | 2017.04.24 |
| HDFS 네임노드에서 metadata size 한계는 어떻게 될까? (0) | 2017.04.24 |
| [하둡완벽가이드] 3장 HDFS (0) | 2017.04.19 |
| Hadoop shell 사용법 (0) | 2016.02.10 |