Inflearn에서 NLP 강좌인 "예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지" 강좌를 들으며 정리한 글입니다. 섹션3까지는 사전 준비 과정이라 별도로 정리하지 않았습니다.
Tokenizing & One-hot Encoding
Tokenizing
전체 테스트를 원하는 구분 단위로 나누는 것
One-hot Encoding
범주형 값(Categorical Value)을 이진화된 값(Binary Value)으로 바꿔서 표현하는 것

- Integer Encoding 문제점은 정수 값으로부터 잘못된 경향성을 학습하게 될 수도 있음
- “개”(=1) 와 “말”(=3)의 평균(1+3/2=2)은 “고양이”(=2)이다. => 명백히 잘못된 학습
- (전통적으로) 단어 하나를 One-hot Encoding 형태로 표현
- 벡터 크기는 사용하는 Vocabulary Set 의 크기
- 단어 표현이 희박(Sprase)해 지게 됨 => 매칭된 단어 외에 값은 모두 0
자연어처리를 위한 기초수학
랜덤변수 (Random Variable)
결합확률 (Joint Probability)
- 여러 개의 사건이 동시에 일어날 확률을 의미
- 두 사건이 독립일 경우 => P(A,B) = P(A)P(B)
조건부 확률 (Conditional Probability)
- 특정 사건이 발생했을 때 다른 사건이 발생할 확률을 의미
- P(B|A) = P(A,B)/P(A)
- 자연어 처리에서 광범위하게 사용되는 개념
- 특정 단어들이 파악이 되었을 때 그 다음에 올 단어들의 확률 계산
- 어떤 조건이 주어졌을 때 이후 사건의 확률
🌟 MLE (Maximum Likelihood Estimation)
- 최대가능도추정
- 어떤 현상이 발생했을 때 그 현상이 발생할 확률이 가장 높은 우도(Likelihood)를 추정하는 방법론

- 이런 현상이 발생할 확률이 가장 높은지를 추정
- 머신러닝 뿐만 아니라 자연어처리 분야에서도 광범위하게 사용
- 어떤 현상이 발생했을 때 그 현상이 발생할 확률이 가장 높은 우도(Likelihood)를 추정하는 방법론
Laplacian Smoothing(강의 자료에 나온 정보는 아님)
- 빈도, 확률 기반으로 모델링을 하다보면 빈도가 0 (확률도 0)인 경우는 제외되는 현상 => 과적합(overfitting) 함정에 빠지기 쉬움
- 추천을 예로들면 어떤 사용자가 본 적이 없는 콘텐츠(장르나 도메인)를 추천할 수 없는데, Laplacian Smoothing을 거치면 추천할 확률이 낮지만 0은 아니게 됨
- NLP 뿐만 아니라 다른 영역에서도 중요
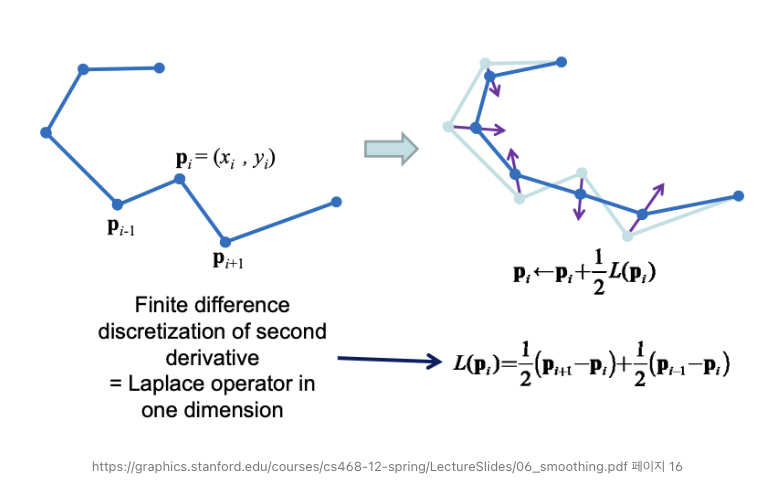
(수식은 다소 복잡하고 어려울 수 있는데, 그림만 보면 좀 이해가 편할 듯 하여 가져옴) - 참고: https://redstarhong.tistory.com/310
Laplacian Smoothing / GraphCNN
Laplacian Smoothing 복습하다가 발견한 사실인데, math의 graph theory에서 정의하는 laplacian matrix이랑 computer vision과 computer graphics에서 정의하는 laplacian operation이 다른 것 같음. Graph theory에서는 Degree matrix
redstarhong.tistory.com
NLTK 라이브러리
자연어 처리를 위한 토크나이징 등 편리한 기능을 제공하는 자연어처리 파이썬 라이브러리
- 다양한 function을 제공하고 있음.
- NLP 실무에서 실제로 많이 사용되는지는 잘 모르겠음



