Inflearn에서 NLP 강좌인 "예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지" 강좌를 들으며 정리한 글입니다. 섹션3까지는 사전 준비 과정이라 별도로 정리하지 않았습니다.
One-hot Encoding 문제점
- 데이터 형태가 Sparse 하다 (1인 경우보다 0인 경우가 많다)
- 유사한 의미를 가진 단어 간의 연관성도 표현할 수 없다.

Embeding 개념
Sparse 한 One-hot Encoding 의 데이터 표현을 Dense 한 표현형태로 변환하는 기법

- Embeding Vector 적절한 값을 찾아야...
- 초기값을 가져다 사용할 수도 있고
- 학습 과정에서 찾아갈 수도 있음 (fine tuning)
- Embedding 장점
- 차원 축속 효과 (Vector 계산으로...)
- Dense 한 데이터로 표현 => DL이 학습하기 용이
- 유사한 의미 단어 벡터들 간의 덧셈과 뺄셈을 수행할 수 있다.

- https://word2vec.kr/search/

Embedding Vector를 tSNE를 이용하여 좌표 평면에 그려봄 (유사 단어는 가까이 위치)
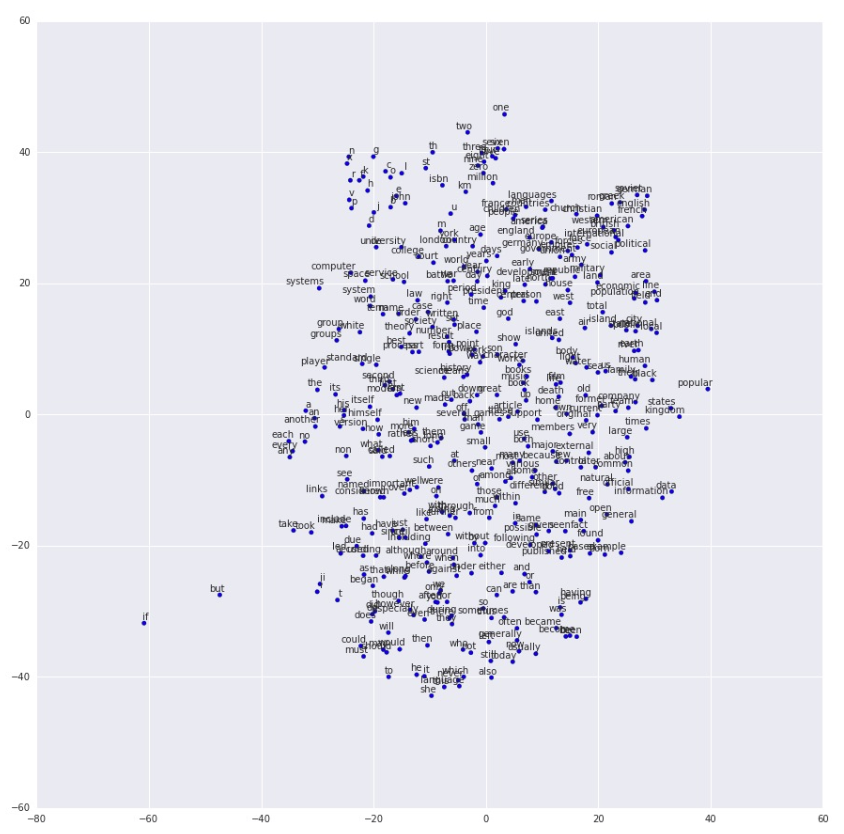
Embedding 모델들
- Word2Vec: 2013년 Google에서 제안한 Embedding을 위한 DL 모델
- FastText: 2016년 Facebook에서 제안한 Embedding을 위한 DL 모델
- BERT: 2018년 Google에서 제안한 고성능 Embedding 모델
Word2Vec
1. CBOW(Continuous Bag-Of-Words)
- Source Context(Input) => Target Words(Output) 예측
- 작은 규모의 데이터 셋에서 유리
2. Skip-Gram model
- Target Words (Input) => Source Context 예측(Output)
- 큰 규모의 데이터 셋에서 유리

Skip-Gram 모델
- Context를 Target 단어의 왼쪽과 오른쪽 단어들의 윈도우로 정의
- window size = 1 인 경우
- Input: the quick brown fox jumped over the lazy dog
- ([the, brown], quick), ([quick fox], brown), ([brown, jumped], fox), ...
- window size = 1 인 경우
- Target 단어로부터 Context를 예측
- (quick, the), (quick, brown), (brown, quick), (brown, fox), ...
전통적으로 maximum likelihood (ML)을 통해서 트레이닝을 진행
히스토리 h("history") => Target Words Wt("target")의 확률을 최대화 하기 위해서 Softmax function을 사용
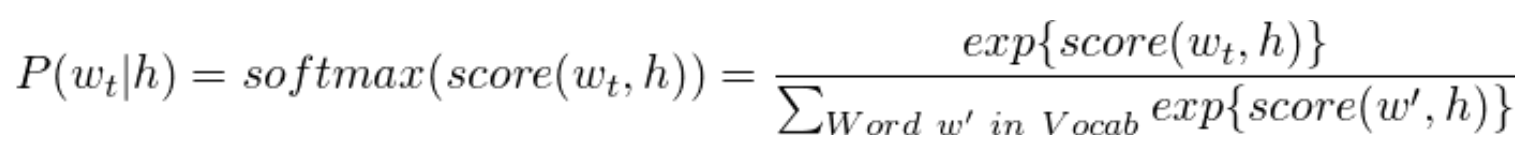

- 정규화된 확률 모델 산출
- 계산 비용이 매우 큽니다.
- 모든 트레이닝 스텝에서 현재 컨텍스트 h에서 어휘(Vocab)에 포함된 모든 단어 w에 대한 확률을 계산하고 정규화해야 하기에
Noise-Contrastive 트레이닝
- CBOW와 Skip-Gram 모델은 이진분류(Binary Classification) 방법(Logistic Regression)을 이용
- 동일 Context에서 k개의 상상의 단어(noise)와 진짜 타겟 단어를 식별

- Qθ (D = 1|wt,h) 는 데이터셋 D에서 컨텍스트 h에서 관찰한 단어가 w일 이진 로지스틱 회귀분석에서의 확률
- 미리 학습된 Embedding Vector θ 를 이용하여 계산
- (실제 상황에서) k개의 대비되는 단어(Noise)들을 Noise Distribution 에서 구하고 이를 평균을 취해서 계산 (몬테카를로 평균)
- 실제 단어에는 높은 확률(Qθ (D = 1|wt,h)), 노이즈 단어들에는 낮은 확률(kEw~Pnoise[logQθ(D =0|~w,h)])
- Negative Sampling
- 전체가 아닌 K개 noise 단어만 계산하면 되므로 학습시간에 이득이 있음
Word2Vec 실습
Embedding Projector 에서 tSNE 분석을 해 볼 수 있다.




