Inflearn에서 NLP 강좌인 "예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지" 강좌를 들으며 정리한 글입니다. 섹션3까지는 사전 준비 과정이라 별도로 정리하지 않았습니다.
Transformer
BERT 등 기본 모델이 됨
- ANN (1950s) => CNN / LSTM (1980s) => Transformer(2017)
- 딥러닝 구조 중 하나
- seq2seq 모델 기반 + (RNN이 아닌) Attention 기법을 적용
장점
- 특징들의 시간적, 공간적 연관관계에 대한 선행을 가정하지 않음
- RNN처럼 순차적인 형태가 아닌 병렬적 계산 가능
- 멀리 떨어진 정보들에 대한 연관관계를 학습
- 시계열 처리에서도 도전적인 문제
- Attention Vector를 길게 잡아서 멀리 있는 정보까지 가중치를 줄 수 있게됨 => 아마도 메모리를 많이 쓸 듯?
Transformer Architecture

- Encoding + Decoding
- RNN과 다르게 Multi-Head Attention + Feed Forward 모델이 추가됨
Positional Encoding
- RNN처럼 순환 피드백이 없음
- 문장 내 해당 단어의 위치에 대한 정보 (Encoding, Decoding에 모두 활용)
- 아래와 같이 계산됨
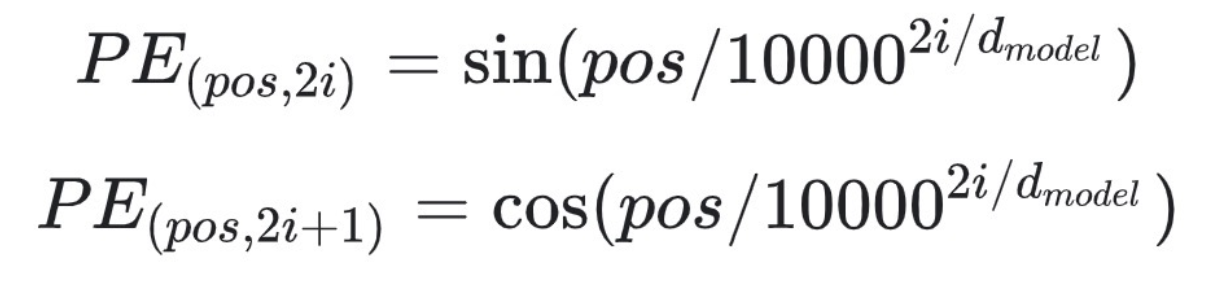
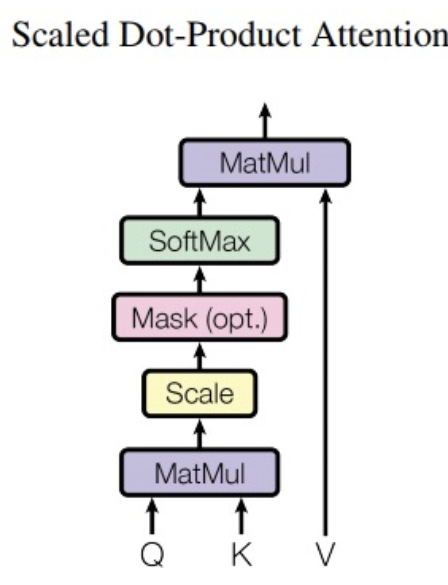
Scaled Dot-Product Attention
Vector를 Q(Query), K(Key), V(Value) 로 나눠서 계산
- Python에서 Dictionary 구조

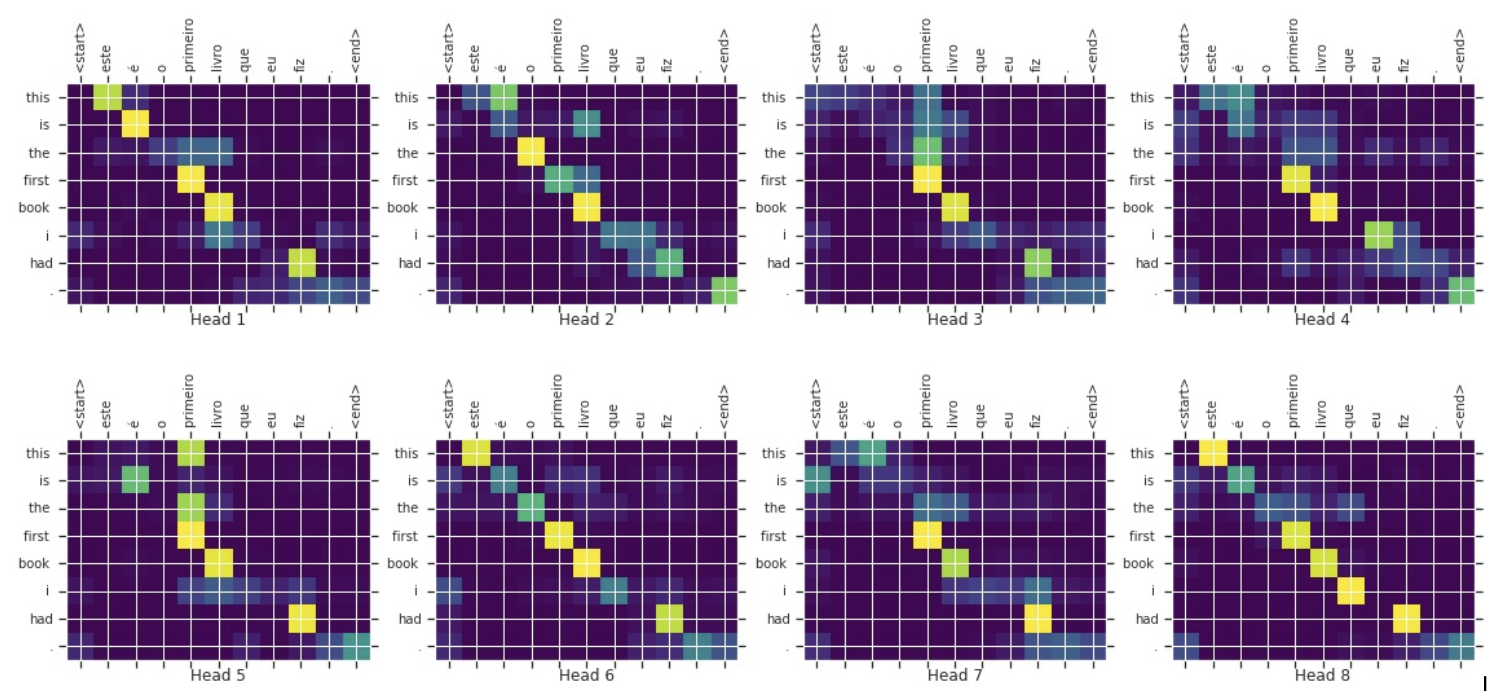
Multi-Head Attention

- Head의 갯수는 Hyper Parameter로 사전에 지정
- 여러 개의 Head에서 학습된 Attention Vector를 Concat해서 활용
- Head별로 가중치 정도를 다르게 학습하기에 다양한 단어들 간의 관계를 학습할 수 있음

Feed Forward
- 2개의 Fully Connected Layer와 ReLU activation으로 구성된 NN(Neural Network)
- Hidden Layer(2048개) + Output Layer(512개)
(Head=8)