Inflearn에서 NLP 강좌인 "예제로 배우는 딥러닝 자연어 처리 입문 NLP with TensorFlow - RNN부터 BERT까지" 강좌를 들으며 정리한 글입니다. 섹션3까지는 사전 준비 과정이라 별도로 정리하지 않았습니다.
BERT
Bidirectional Encoder Representations from Transfomers
- 2018년 공개된 논문
- (이 논문 이후로) NLP Task에서도 빅 모델의 시대를 연 모델
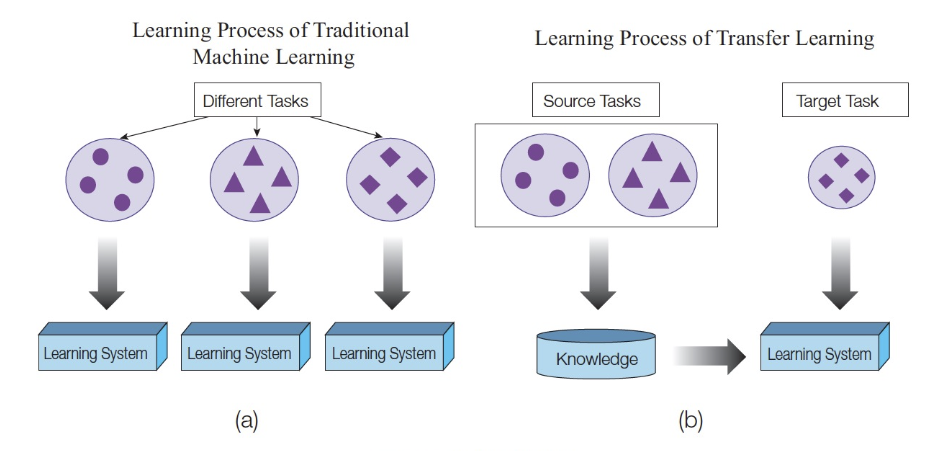
전이 학습 (Transfer Learning)
- Transfer Learning(= Fine-Tuning)는 이미 학습된 NN 파라메터를 새로운 Task에 맞게 다시 미세 조정하는 것을 의미
- 컴퓨터 비전 문제에서는 ImageNet 등의 데이터 셋에서 미리 Pre-Traning => 풀고자 하는 문제에 맞게 Fine-Tuning 과정을 거침
- ImageNet: 120만장 1000개의 레이블을 가진 데이터
- BERT 이후로 기본 방식이 됨
BERT의 핵심 아이디어
대량의 단어(Corpus)로 양방향(Bidirectional) 학습시킨 Pre-Trained 자연어 처리 모델을 제공 => 마지막 레이어에 ANN 등 추가만을 통해 Fine-Tuning

BERT Input

- [CLS] : 두 개의 문장을 통해 학습하는데, 두 개의 문장이 어어짐을 알려주는 Special Token
- [SEP] : 두 개의 문장을 구분하는 Special Token
- Input
- Position Embeddings : (Transformer 에서 설명한) 위치 가중치 Vector
- Segment Embeddings : 문장 단위 Embedding Vector
- Token Embeddings : 단어별로 Embedding Vector
Pre-Training BERT
- Task1
- Masked LM(MLM)
- Input 데이터 일부를 Mask Token으로 변경 후 예측하는 학습을 수행
- 랜덤하게 15%를 Mask 대상으로 선정
- 그 중 80%(Mask), 10%(랜덤 토큰, 임의의 단어), 10%(그대로 유지)
- Masked LM(MLM)
- Task2
- Next Sentence Prediction (NSP)
- 2개의 문장(Segment A/B)이 이어지는지 아닌지 학습
- 50%(이어지는 문장), 50%(이어지지 않는 문장)
- Dataset
- BooksCorpus (800M words), English Wikipedia (2,500M words)
- MLM과 NSP loss를 최적화 하는 방향으로 학습
- BERTBASE : (L=12, H=768, A=12, Total Parameters=110M) => 1억1천만
- 4 Cloud TPUs in Pod configuration (16 TPU chips total)
- BERTLARGE : (L=24, H=1024, A=16, Total Parameters=340M) => 3억4천만
- 16CloudTPUs(64TPUchips total)
오픈소스로 공개된 BERT
- 사전 학습된 BERT 모델 위에 Fine-Tuning이 가능해짐
- 구현체: https://github.com/google-research/bert




