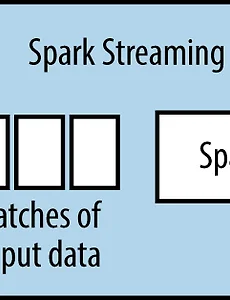
BigData66 데이터 마이닝 Study 로드맵 페이스북 통계마당 그룹에서 어떤 분이 올려주신 공부 로드맵이다.평소에 데이터마이닝 쪽에 관심이 많아서 혼자 공부하던 중에 도움이 될 것 같아서 복사해 두었다. 내용만 복사 해 두어서 어떤 분이 작성했는지는 기억이 나질 않는다. 그 분께 감사하다고 이야기 하고 싶다. # 데이터마이닝 공부 로드맵 for 파이썬제목과 관련하여 얼마전에 정리한 내용이 있어 공유 드립니다. 제가 공부한 과정이기도 하고, 제가 운영하는 연구실의 코스웤이기도 합니다. 현재 학교에서도 이 코스로 MOOC 강좌를 개발하고 있습니다... 언제 끝날지는 ㅎㅎ 필요하신 분께 도움이 되었으면 합니다.1) 리눅스 공부: 데이터 분석을 위해서는 리눅스와 command line interface(CLI)에 익숙해 져야 합니다. 리눅스 공부를 먼저 .. 2016. 1. 20. Flume RpcClient 사용기 Flume Avro 데이터를 전송하기 위한 방법은 몇가지가 있으나, 보통 쉬운 log4j appender 를 이용하는 것으로 알고 있다. log4j appender 의 경우 flume-ng-sdk.jar 에서 제공되기 때문에 log4j 설정만 하면되는 간편함이 있다. 하지만 log4j 특성상 전송되는 Event 에 Header에 데이터를 포함해서 전송할 수 없다. 만약 Flume 으로 데이터 전송시 Header 에 원하는 데이터를 전달할 수 있다면, Multiplexing 설정을 통해 좀 더 General 한 source-channel-sink 구조를 만들 수 있을 것이라 생각했다. 이를 위해서 Flume 에서 제공되는 것이 RpcClient 클래스이다. Flume 1.6.0(최신버전 at 2016/01.. 2016. 1. 20. Learning Spark Chapter. 10 Spark Streaming RDD 개념을 갖고 있는 Spark 와 유사하게 Spark Streaming 은 DStream 또는 Discretized Streams 라고 불리는 추상개념을 갖고 있다. DStream 이란? 시간 흐름에 따른 순차적 데이터를 의미한다. 내부적으로 DStream 은 각 시점에 RDD 시퀀스이다. DStream 은 Flume, Kafka 또는 HDFS 같은 많은 Input 유형으로 부터 생성될 수 있다. DStream 에는 두 가지 유형의 Operation 이 제공된다. Transformation DStream 을 생성(파생) Output 외부 데이터 저장소에 결과 저장 기본적으로 RDD 에 제공되는 Operation 과 시간 기반의 Operation(예를 들면 sliding window) 을 제공한다. .. 2015. 8. 20. Learning Spark Chapter. 9 Spark SQL 구조적 데이터(Structured Data)와 반구조적(SemiStructured Data) 를 다룰 수 있는 Spark SQL 과 Spark Interface 를 소개한다. 구조적 데이터란? Schema 를 갖고 있는 데이터를 의미한다. 만약 구조적 데이터를 다룰 때, Spark SQL 을 사용하면 쉽고, 효율적으로 다룰 수 있다. 다양한 데이터 유형 처리 가능 SQL 을 사용하여 쿼리 가능 RDD 와 SQL Table 을 Join 하는 기능을 포함하여 기존 코드(spark-core)와 통합이 가능 이런 기능들을 제공하기 위해 Spark SQL 은 SchemaRDD 를 사용한다. 이는 Row 객체의 RDD 이며, 각 아이템은 Record 를 의미한다. SchemaRDD 는 기존 RDD 와 유사해 보이지.. 2015. 7. 31. 이전 1 ··· 4 5 6 7 8 9 10 ··· 17 다음