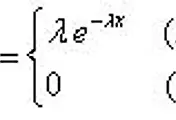Uniform Distribution 균등 분포
1. 연속 균등 확률분포 ㅇ 연속형 확률분포 중 가장 단순한 분포 - 두 점 a,b 사이가 평평한 확률밀도함수를 갖는 확률분포임 . 즉, (a,b) 구간 내에서 면적 1, 높이 1/(b-a)ㅇ 표기 : X ~ U(a,b) ㅇ 확률밀도함수(Probability Density Function, PDF)
ㅇ 누적분포함수(Cumulative Distribution Function, CDF)
ㅇ 기대값(Expectation) - 좌우 대칭적 분포이므로, 기대값 = 중앙값 . 즉, E(X) = (a+b)/2 ㅇ 분산(Variance) - Var(X) = E(X2) - (E(X))2 = (b-a)2/12 ㅇ (a ≤ c < d < b) 일 때,
2. 이산 균등 확률분포 ㅇ 각각의 시행 확률변수 값이 모두 동일한 분포
ㅇ 표기 : X ~ DU(1,N) ㅇ 확률질량함수(Probability Mass Function, PMF)
ㅇ 기대값(Expectation) - E(X) = (N+1)/2 ㅇ 분산(Variance) - Var(X) = (N2-1)/12 3. 표준 균일 분포(Standard Uniform Distribution) ㅇ Y=(x-a)/(b-a) ~ U(0,1)






'BigData > 수학이론' 카테고리의 다른 글
| 확률분포 > 포아송분포 (0) | 2015.03.17 |
|---|---|
| 확률분포 > 지수분포 (0) | 2015.03.17 |
| 확률분포 > 정규분포 (0) | 2015.03.17 |
| 거리(distance) 구하기 (0) | 2015.03.16 |